1. 서론
최근 인공신경망(Artificial Neural Network) 알고리즘은 이미지 인식, 음성 인식, 자연어 처리 등의 다양한 분야에서 비약적인 성능향상을 보이고 있으며, 이로 인하여 학계 및 산업계의 주목을 받고 있다. 향후 인공신경망 알고리즘은 공장 자동화, 의료 서비스, 자율주행 자동차 등의 분야에서 적극적으로 활용될 것으로 예측되며, 이를 효율적으로 처리하기 위한 다양한 하드웨어 구조의 개발이 활발히 진행되고 있다.
▶ 인공신경망(Artificial Neural Network) 알고리즘
: 인공신경망 알고리즘은 생물학의 신경망 모델로 만들어진 학습 알고리즘이다.
최근에는 2개 이상의 층으로 구성된 Multi Layer Perceptron(MLP)중에서 8개 이상의 많은 층으로 구성된 Deep Neural Network(DNN)가 활발히 연구되고 있다.
현재 대부분의 연구자 또는 기업들은 Graphics Processing Unit(GPU)를 이용하여 인공신경망 연산을 수행 중이다. 최근 많이 연구되고 있는 DNN의 경우 대부분 십만개 이상의 뉴런으로 구성되어 있어 연산량이 방대하다. 하지만 간단한 연산들이 반복되고 병렬성이 높기 때문에 다수의 코어를 보유하고 있는 GPU에서 효율적인 연산이 가능하다.
GPU는 범용 연산기로 다양한 구조의 인공신경망 알고리즘을 수행 가능하지만, 각각의 인공신경망 연산에 대해 최적화 되어 있지 않다. 따라서 특정 인공신경망 연산에 대해서는 에너지 대비 연산성능이 더 좋은 가속기 개발이 가능하다.
이러한 동향에 따라, 학계 및 업계에서는 인공신경망 연산 전용 하드웨어 가속기 개발을 위한 연구가 활발히 이루어지고 있다.
2. 인공신경망 알고리즘과 GPU를 사용한 연산과정
GPU의 강력한 병렬 연산 기능을 범용으로 적용하는 General Purpose on GPU(GPGPU)가 제안된 이후, GPU에서 인공신경망 연산의 빠른 수행이 가능해졌다. GPU는 다수의 코어가 존재하는 매니코어(manycore) 구조로, 단순한 연산이 반복되는 인공신경망 연산을 빠르게 처리하는데 적합하다.
DNN은 십만 개 이상의 뉴런들로 구성되어 있기 때문에, 이를 빠르게 연산할 수 있는 하드웨어 플랫폼이 필수적이다.
한 층의 뉴런들은 병렬적으로 연산이 가능하고, 각각의 뉴런은 MAC 연산과 ReLU 연산과 같은 간단한 연산을 수행하기 때문에 매니코어 구조인 GPU에서 높은 성능을 보인다.
▶ MAC(Multiply-ACcumulate) 연산
: 앞선 층의 뉴런들에서 데이터를 입력으로 받고, 각각 파라미터를 곱하여 summation하는 연산
▶ ReLU(Rectified Linear Unit) 함수
: MAC 연산 수행 이후, 다음 층의 뉴런으로 다시 데이터를 전달하는 activation function
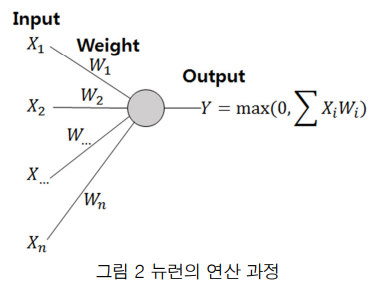
현재 인공신경망 연산들은 대부분 GPU를 통해 충분한 연산 성능에 도달하였으나, 전력 소비 대비 연산 성능의 측면에서 개선의 여지가 있다.
GPU는 특정 인공신경망 연산에 대해 최적화 되어있지 않다. 예를 들어 32bit 변수들의 연산만 수행하는 인공신경망의 경우에는 64bit의 연산기 자원이 낭비된다.
또한, GPU는 작은 용량의 L1 캐시를 가지고 있기 때문에 CNN과 같이 데이터 재사용이 많은 경우에 비효율적이다.
따라서 각 인공신경망에 최적화된 가속기를 설계하면 전력 대비 연산성능의 향상이 가능하다.
3. 최신 인공신경망 연산 하드웨어 가속기 연구 동향
본 절에서는 최신 인공신경망 연산 하드웨어 가속기 연구 동향에 대해 분석한다. 본 절에서는 다양한 기술들이 적용되어 연산 속도를 향상시키고, 전력 소모를 줄인 가속기 연구들을 분류, 소개한다.
3.1 데이터 재사용(Data Reusability)
CNN 인공신경망에서는 연산에서 활용되는 대부분의 데이터는 여러 번 재사용되는 특징을 가지고 있다.
인공신경망 연산을 GPU에서 수행할 경우, 작은 용량의 L1 캐시로 인해 동일한 데이터를 여러 번 접근하는 문제가 발생한다.
재사용되는 특징을 활용하지 못하는 한계를 해결하기 위하여, 불러온 데이터의 재사용을 높이는 Row Stationary(RS) dataflow 기술과 이를 활용한 가속기 구조가 제안되었다.
RS는 가속기 내의 Processing Element(PE)에서 사용된 입력, 커널, 출력 데이터를 재사용 될 인접한 PE의 Register File(RF)에 저장한다. 그 결과 RS 방식은 PE에 필요한 데이터를 재사용하므로, 메모리 접근 횟수가 감소하여 에너지 소비량을 감소시킨다.
3.2 데이터 압축
GPU의 연산 정밀도(32-bit 또는 64-bit 부동소수점)는 인공신경망 연산에 활용하기에는 필요 이상으로 과도하게 정밀하다.
1) ReLU 연산으로 인하여 음수 값은 모두 0으로 변환되기 때문에 연산 중 많은 데이터 값이 0이다. 0값을 가지는 데이터들이 뉴런의 입력 값으로 들어갈 경우, MAC 연산 수행 시 불필요한 연산이 된다. 이러한 0을 곱하는 연산들은 모두 생략이 가능하다.
따라서 이러한 데이터의 0값을 제거하기 위해 데이터 압축 기술이 제안되었다. 압축 기술은 각 층의 연산을 수행하기 전, 이전 층의 non-zero 뉴런만을 따로 저장하는 버퍼를 추가하여 0값을 제거한다. 0값을 제거함으로 인해 현 층에서 불필요한 연산을 수행하지 않기 때문에 인공신경망 연산성능이 향상된다.

2) 또한, 인공신경망 연산은 일반적으로 32-bit floating point 형태로 연산이 되는데, 32-bit보다 적은 bitwidth의 형태로 연산하여도 인공신경망 성능에 큰 영향이 없는 것으로 알려져 있다.
이와 관련하여 software적인 방법을 통해 감소된 bitwidth의 연산으로 인공신경망 성능 저하를 최소한으로 하고 수행 속도를 향상시킨 연구가 제안된 바 있다. 앞서 언급된 바와 같이 최소한의 bitwidth를 사용하면 인공신경망의 연산 성능을 향상시킬 수 있고, 메모리 접근에 대한 병목 현상도 해결할 수 있다.
구체적으로, bitwidth를 줄이게 되면, 중복되는 파라미터들이 많이 생기게 된다. 이때 같은 값을 가지게 되는 파라미터들은 index 정보만을 저장하여 저장 공간을 절약할 수 있다. 그 결과로 기존의 bitwidth를 사용했을 때보다 총 메모리 접근 수가 감소한다.

3.3 Processor-In-Memory (PIM)
PIM은 메모리 내부에 연산 장치를 융합시켜 데이터의 이동을 최소화시킨 구조다.
DNN은 많은 양의 파라미터를 메모리에서 불러오기 때문에, 메모리 접근에서 병목현상이 발생한다. 이러한 문제를 최소화하기 위해 PIM 구조를 활용한 가속기가 제안되었다.
Hybrid Memory Cube(HMC)는 연산장치로 이루어진 logic layer 위에 DRAM을 3차원으로 쌓은 구조다. HMC 구조의 메모리 시스템은 메모리 대역폭이 넓기 때문에, DNN 연산에서의 메모리 병목 현상으로 인한 연산 성능 하락을 최소화하기에 적합하다.

3.4 DianNao Project
DianNao project는 CNN, DNN을 포함한 머신러닝 가속기 구조 개발을 목표로 시작되었다. DianNao project의 궁극적인 목표는 한정된 면적으로 성능 및 에너지 효율을 최적화하여 일반적인 수준의 컴퓨터 시스템 환경에서 인공신경망 알고리즘을 실행 가능한 가속기를 설계하는 것이다.
1) DianNao: 많은 데이터 처리 --> 메모리 성능 및 소모 에너지 최적화에 중점을 둔 CNN 및 DNN 가속기
2) DaDianNao: compute intensive, memory intensive 인공신경망 --> multi-chip 형태의 가속기
3) PuDianNao: 복수의 머신러닝 기법을 활용하는 어플리케이션 --> 머신러닝 기법을 지원하는 가속기
4) ShiDianNao: 이미지를 입력으로 사용하는 어플리케이션 --> 머신러닝을 활용하는 이미지 어플리케이션에서의 실행성능 및 에너지 효율 최적화에 특화된 가속기
5) Cambricon: 다양한 종류의 신경망 기술을 동시에 지원 --> 신경망 가속기를 위한 Instruction Set Architecture(ISA)
4. 결론
본 연구에서는 인공신경망 연산을 위한 하드웨어 가속기와 관련된 최신 연구 동향을 소개하였다.
GPU는 현재 인공신경망 연산을 위한 하드웨어로 가장 많이 사용되고 있으며, GPU에서 인공신경망 연산 효율을 늘리기 위한 연구가 진행되고 있다.
출처: https://www.dbpia.co.kr/journal/articleDetail?nodeId=NODE07013359
인공신경망 연산을 위한 하드웨어 가속기 최신 연구 동향 | DBpia
박종현, 김민식, 김윤수, 이경민, 윤명국, 노원우 | 정보과학회지 | 2016.9
www.dbpia.co.kr
'논문' 카테고리의 다른 글
| GPU Register File의 Bank Conflict 분석 (0) | 2023.08.24 |
|---|---|
| GCN 아키텍쳐 상에서의 OpenCL을 이용한 GPGPU 성능향상 기법 연구 (0) | 2023.08.22 |
| GPU 컴퓨팅에서 빠른 데이터 전송을 위한 메모리 피닝 자동 관리 (0) | 2023.08.21 |
| 다중 워크로드 환경을 위한 GPGPU 스레드 블록 스케줄링 (0) | 2023.05.05 |
| GPU 메모리 접근 시간 부채널 특성 분석 (0) | 2023.05.01 |


