요약
최근 반도체 공정 기술이 발달함에 따라 단일 프로세서에 적재되는 코어의 수가 크게 증가하였고, 이는 프로세서의 성능을 급격하게 향상시키는 계기가 되고 있다. 특히, 많은 수의 코어들로 구성된 GPU(Graphics Processing Unit)는 대규모 병렬성을 활용하여 연산처리 성능을 크게 향상시키고 있다.
- Problem: 하지만 주 메모리 접근 지연시간이 GPU의 성능 향상을 제약하는 심각한 요인 중 하나로 제기되는 상황이다.
- Solution: 본 논문에서는 3차원 구조를 통한 GPU의 메모리 접근 효율성 향상에 대한 정량적 분석과, 3차원 구조 적용 시 발생 가능한 문제점에 대해 살펴보고자 한다.
일반적으로 메모리 명령어 비율은 평균적으로 전체 명령어의 30%를 차지하고, 메모리 명령어 중에서 주 메모리 접근과 관련된 글로벌/로컬 메모리 명령어가 차지하는 비율 또한 평균 60%이므로, 주 메모리로의 접근 지연시간을 크게 감소시키는 3차원 구조를 적용한다면 GPU의 성능 또한 크게 향상시킬 수 있을 것으로 예상된다.
그러나 본 논문에서 수행한 실험 결과에 따르면, 메모리 병목현상으로 인해 3차원 구조 GPU의 성능이 2차원 구조 GPU에 비해 크게 향상되지는 않음을 확인할 수 있다.
1. 서론
▶ GPU(Graphics Processing Unit)
단일 프로세서에 적재되는 코어의 수가 크게 증가하고 있다. 특히, 코어 개수의 증가를 통한 성능 향상은 그래픽 전용 연산 유닛인 GPU(Graphics Processing Unit)에서 더욱 두드러지게 나타난다.
다수의 코어로 구성된 GPU는 프로그램을 스레드(Thread) 단위로 구분하여 연산을 수행한다. GPU 내에 내장된 다수의 코어들은 독립적으로 스레드를 수행할 수 있기 때문에, 코어의 개수가 증가할수록 더욱 많은 수의 스레드를 동시에 처리함으로써 연산 속도를 향상시킬 수 있다.
그러나 단순히 코어의 개수를 증가시키는 것이 성능을 효율적으로 향상시킬 수 있는 것은 아니다. 이상적으로 GPU 내에 코어들이 효율적으로 스레드를 처리한다면 성능 향상에 도움이 되지만, 코어에 스레드가 적절하게 분배되지 않으면 성능 향상의 이득을 볼 수 없다. 즉, GPU가 구조적 특성을 효율적으로 활용하기 위해서는 스레드가 여러 코어에 적절하게 분배되어야 한다.
▶ GPU의 효율적인 스레드 분배
주로 스레드 분배와 관련된 연구들은 GPU 내의 스레드 스케줄러의 구조를 변경하는 연구가 주를 이루었다.
- Problem: 근본적으로 많은 수의 스레드를 코어에 할당하기 위해서는 대용량의 주 메모리에서 데이터를 인출하는 과정이 필요하다. GPU에서는 주 메모리의 데이터를 인출하기 위해 메모리 인터페이스를 거치는데, 이 때 추가적으로 발생하는 지연시간이 400~600사이클에 육박한다.
- Solution: 스레드를 분배하기 위해 주 메모리의 데이터를 인출하는 과정에서 발생하는 지연 시간을 줄인다면 성능 향상에 더욱 도움이 될 것이다.
--> 물리적인 해결책: 3차원 적층 기법
▶ 3차원 적층 기법
: 여러 개의 코어를 수직으로 적층시켜 TSV(Through Silicon Via)로 연결함으로써 내부 연결망의 길이를 크게 줄여주어 프로세서의 성능을 향상시키는 기법
--> 3차원 적층 기법을 활용한다면, 주 메모리와 GPU 사이의 접근 지연 시간 문제를 해결할 수 있으므로, GPU의 성능을 크게 향상시킬 수 있을 것으로 기대된다.
이에, 본 논문에서는 GPU와 주 메모리를 수직으로 연결하는 3차원 구조 GPU를 통한 메모리 접근 측면에서 성능 향상 효과를 분석하고자 한다.
2. 연구 배경
▷ CPU에서의 3차원 구조 연구
- 2차원 CPU 구조에 비해 3차원 CPU 구조는 더 많은 다이를 쌓음으로써, 배선 길이를 크게 감소시킬 수 있다.
하지만 많은 다이를 쌓음으로 인해 발열 문제가 발생하는데, 이는 3차원 구조의 치명적인 단점이다. - 3차원 CPU 구조는 2차원 CPU 구조에 비해 배선 길이가 짧다. 배선 길이가 짧아지면 전력 소모 또한 크게 줄어든다.
- 2차원 CPU 구조에서 문제가 되고 있는 내부 연결망 문제를 해결하고자 새로운 L2 캐쉬 구조를 제안한다. 데이터 이동 기법을 활용하는 3차원 L2 캐쉬 구조를 활용하여 2차원 구조에 비해서 IPC를 향상시켰다.
▶ 2차원 구조 멀티코어 프로세서
--> 2차원 구조 멀티코어 프로세서에서의 코어 개수 증가
- 장점: 전체 프로세서의 성능을 높여줄 수 있다.
- Problem: 코어 내부에 적재된 제어 및 연산 유닛들 사이의 통신을 위한 내부 연결망의 길이는 상대적으로 증가하게 된다.
내부 연결망의 증가는 유닛 간의 통신 지연을 발생시킬 가능성이 높다. 또한, 연결망의 길이 증가는 연결망에서 발생하는 전력 소모량을 증가시켜, 프로세서의 신뢰성에 악영향을 줄 수 있다.
▶ 3차원 구조 멀티코어 프로세서
: 3차원 구조 멀티코어 프로세서는 2개 이상의 층이 수직으로 적층된 구조로 구성된다. 각 층에는 프로세서의 핵심 유닛들이 위치하게 되고, 각 층은 수직으로 연결된 TSV를 이용하여 통신이 가능하다.
- Solution: TSV를 이용한 내부 유닛 간의 수직 연결은 2차원 구조 멀티코어 프로세서에서의 코어 개수 증가로 인한 내부 연결망에서의 지연시간 증가 문제를 위한 좋은 해결책으로 기대된다.
▷ 기존의 GPU 연구
- SISD(Single Instruction Single Data stream) 구조에서 큰 공유 메모리로 인해 유발되는 메모리 접근 지연시간을, 문맥 교환(Context switching)을 활용하여 감출 수 있도록 하는 Horizon System을 제안한다. Horizon System에서는 높은 연산 처리량을 확보하기 위해 FU(Functional Unit)들을 파이프라인화 하고 있을 뿐 아니라, 하드웨어 기법을 통해 자원들의 익명성과 독립성 또한 확보한다.
- 단일 워프(warp)가 추가적인 레지스터 파일 공간을 요구하지 않으면서 스케줄러의 슬롯 중 하나 이상을 차지하도록 허용하는 DWS(Dynamic Warp Subdivision) 기법을 제안한다. 독립적인 개체(entity)들은 프로그램 수행 중에 분기를 허용하며, 앞서 적중되어 수행된 스레드들을 포함할 수 있도록 허용한다. 이를 통해 DWS 깁버은 메모리 수준의 병렬성을 향상시키고 지연시간을 감출 수 있게 된다.
- 다중 스레드 선출 기법(Many-Thread aware Prefetching)을 활용하여 GPGPU 시스템에 적합한 새로운 하드웨어와 소프트웨어 선인출 기법을 제안한다. Inter-Thread Prefetching이라 불리는 소프트웨어적인 MT-Prefetching 매커니즘은 fine-grained 스레드들 사이의 일반적인 메모리 접근 작용을 이용한다.
- GPU 컴퓨팅에서 생기는 동적 불규칙 문제들을 해결할 수 있는 소프트웨어적인 기법으로 G-Streamline을 제안한다. G-Streamline은 하드웨어 확장이나 오프라인 자료 수집을 요구하지 않는 순수한 소프트웨어적인 해결책으로 불규칙 문제들을 처리하고 최적화 사이에 발생되는 충돌을 해결함으로써 전체 프로그램의 성능을 최대화한다.
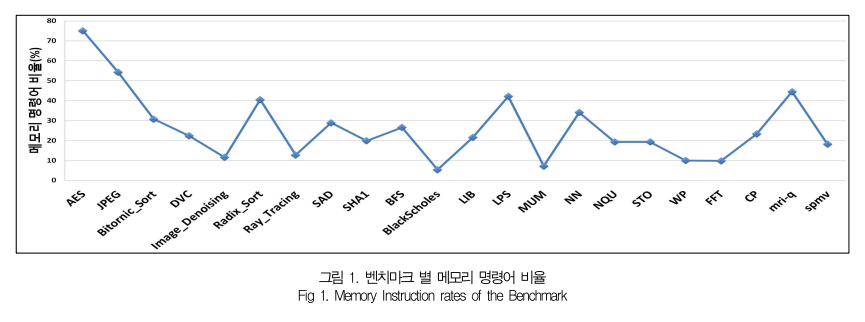
대부분의 벤치마크 프로그램들이 전체 명령어 중 메모리 명령어가 차지하는 비율이 10%가 넘고, 전체적으로는 평균 30% 정도의 비율을 나타냄을 확인할 수 있다. 이러한 결과를 통해 GPU에서 수행되는 연산 명령의 상당 부분들이 메모리 접근 명령임을 확인할 수 있다.
CUDA에서 메모리는 글로벌(Global)/로컬(Local)/컨스턴트(Constant)/공유(Shared)/파라미터(Parameter)/텍스쳐(Texture)와 같이 6개로 구분된다. 이들 중 글로벌 메모리와 로컬 메모리가 GPU의 주 메모리 공간을 할당받는다.
그러므로, 특정 벤치마크에서 메모리 명령어 비율이 높지만, 글로벌/로컬 메모리와 같이 주 메모리 접근이 아닌 캐시 메모리에 존재하는 컨스턴트/공유/텍스처 접근 명령어가 많다면 해당 벤치마크는 2차원 구조 GPU와 비교하여 3차원 구조에서의 성능 향상의 폭이 크지 않을 가능성이 있다.
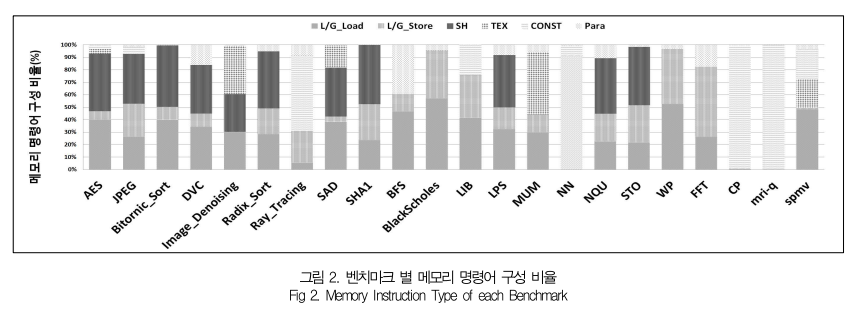
대다수의 벤치마크 프로그램들에서는 글로벌/로컬 메모리와 같이 주 메모리에 접근하는 명령어(L/G_Store, L/G_Load)의 비중이 높음을 확인할 수 있다.
4. 실험 결과
1) 성능 변화 분석
▷ 메모리 명령어 비율이 높을수록 3차원 구조 GPU에서 성능 이득을 많이 얻을 수 있을 것이라는 예상과는 다른 결과를 보인다.
- 원인 1) 3차원 구조 GPU의 장점: 주 메모리 접근 지연시간 감소
--> 메모리 명령어 비율은 높지만, 실제 사이클 당 메모리 접근 비율이 낮은 경우에는 3차원 구조 GPU의 장점의 효과가 미미하다. - 원인 2) 3차원 구조 GPU에서는 사이클 당 주 메모리 접근 횟수가 2차원 구조와 비교하여 증가한다. 즉, 주 메모리 접근 지연시간은 감소하지만, 접근 횟수가 증가하는 문제가 발생하는 것이다.
▷ 높은 성능 향상을 나타내는 벤치마크 프로그램
- 메모리 접근 비율이 높다.
- 3차원 구조 GPU로 인한 주 메모리 접근 지연시간 감소에 의해, 메모리 접근 비율이 상승한다.
▷ 낮은 성능 향상을 나타내는 벤치마크 프로그램
- 메모리 접근 비율이 낮다.
- 3차원 구조 GPU로 인한 주 메모리 접근 지연시간 감소에도 불구하고, 메모리 접근 비율 향상이 거의 없다.
- 메모리 접근 비율이 높음에도 불구하고 3차원 구조 GPU에서 메모리 접근 비율 향상이 미미한 경우도 있다.
- 높은 메모리 접근 비율을 나타내며 3차원 구조를 통해 메모리 접근 비율이 상당함에도 불구하고, 오히려 성능적인 측면에서 감소하는 경우도 있다.
--> 즉, 3차원 구조 GPU에서 2차원 구조 GPU와 비교하여 낮은 성능 향상을 보이는 이유는 GPU에서 주 메모리 접근 시간의 감소를 통한 전체 수행 사이클 감소 효과를 제대로 활용하고 있지 못하기 때문인 것으로 분석된다.
2) 데이터 전송 지연 시간
▶ 3차원 구조 GPU
: 2차원 구조 GPU와 달리 3차원 구조 GPU에서는 코어와 주 메모리가 TSV를 이용하여 연결되기 때문에, 주 메모리 접근 지연시간이 매우 큰 폭으로 감소한다.
- Problem: 2차원 구조 GPU와 비교하여 짧은 시간 내에 메모리의 데이터가 GPU에 도착하므로, 이에 따른 메모리 병목 현상이 발생할 가능성이 존재한다.
--> 3차원 구조 GPU에서 발생하는 데이터 전송시간의 지연 증가 문제는 주 메모리 접근 지연시간 감소에 의한 성능 향상 효과를 저해시키는 주된 요인으로 분석된다. 즉, 3차원 구조 GPU에서 메모리 인터페이스에서 발생하는 병목현상으로 인한 데이터 전송 지연시간 증가 문제는 성능 향상을 저해하는 가장 큰 원인으로 분석된다.
- Solution: 메모리 접근을 효율적으로 하기 위하여 메모리 인터페이스의 수를 변경하여 실험을 수행한다.
--> 메모리 인터페이스 수가 4개에서 6개, 8개, 10개, 12개로 증가할수록 성능 또한 비례하여 증가한다.
--> 메모리 인터페이스에서 발생하는 병목현상을 제거할 수 있는 방법을 적용하면, 3차원 구조 GPU의 성능을 더욱 향상시킬 수 있을 것이다.
5. 결론
본 논문에서는 기존의 2차원 구조 GPU와 비교하여 주 메모리 접근 시간을 줄여줌으로써 성능을 크게 향상시킬 수 있는 3차원 구조 GPU의 성능 변화 양상 및 추가적으로 발생할 수 있는 문제점에 대해 분석하였다.
▶ 3차원 구조 GPU에서 수행되는 벤치마크 프로그램들의 성능 향상이 낮은 이유?
- 벤치마크 별로 나타나는 메모리 명령어 비율이 사이클 당 메모리 접근과는 상관이 없다.
- 메모리 접근 시간 감소로 인한 메모리 접근 비율 향상에도 불구하고 성능 향상을 보이지 못한 경우들이 존재하였다.
▶ 3차원 구조 GPU의 장점(주 메모리 접근 시간 감소)에도 불구하고 성능 향상을 보이지 못한 이유?
- 코어와 주 메모리 사이에서 발생하는 내부 병목현상 문제가 3차원 구조 GPU에서 더욱 심화되었다.
▶ 결론
- 3차원 구조 GPU를 구성할 때, 단순히 구조 변경을 통한 주 메모리 접근 지연시간 감소 효과에 의한 성능 향상만을 고려한느 것이 아니라, 코어와 주 메모리 사이의 병목현상에 의한 데이터 전송 지연시간의 증가 문제 또한 고려해야 한다.
2차원 구조 대비 3차원 구조 GPU의 메모리 접근 효율성 분석 | DBpia
전형규, 안진우, 김종면, 김철홍 | 한국컴퓨터정보학회논문지 | 2012.07
www.dbpia.co.kr
'논문' 카테고리의 다른 글
| 워프 스케쥴링 기법에 따른 GPU 성능 분석 (0) | 2023.09.03 |
|---|---|
| 효율적인 GPU 메모리 컨트롤러 설계를 위한 GPU 메모리 성능 분석 연구 (0) | 2023.08.31 |
| GPU 공유 메모리 크기에 따른 최적화 기법 (0) | 2023.08.31 |
| SIMT 구조 GP-GPU의 명령어 처리 성능 향상을 위한 Dispatch Unit과 Operand Selection Unit 설계 (0) | 2023.08.24 |
| GPU Register File의 Bank Conflict 분석 (0) | 2023.08.24 |


