요약
본 논문은 그래픽 처리 뿐 아니라 범용 연산의 가속화를 지원하기 위한 SIMT 구조 GP-GPU의 DIspatch Unit과 Operand Selection Unit을 제안한다.
- Problem
: Warp Schedular로부터 발행된 명령어에서 사용되는 Operand의 모든 정보를 Decoding하면 불필요한 Operand Load가 발생하여 레지스터 부하가 발생한다. - Solution
: 이러한 문제점을 해결하기 위해 Pre-decoding 방법을 사용하여 Operand의 정보만을 먼저 Decoding하여 Operand Load를 줄이고, 레지스터의 부하를 줄일 수 있는 방법을 제안한다.
제안하는 Dispatch Unit에서 나온 Operand 정보들을 레지스터 뱅크 충돌을 방지하는 방법을 적용한 Operand Selection Unit에 전달해, 전체적인 처리 성능을 향상시켰다.
1. 서론
▶ GPGPU
많은 연산량을 요구하는 어플리케이션들이 등장하게 되면서 CPU 단독으로 실행할 때 처리 속도가 늦어지는 문제가 발생하게 되었다. 이를 해결하기 위해 단순히 그래픽 처리 역할만 하였던 GPU를 많은 양의 범용 연산을 병렬로 처리하기 위해 GP-GPU의 형태로 발전시켰다. SIMT(Single Instruction Multiple Thread) 구조의 GP-GPU는 하나의 명령어로 여러 Thread를 동작하여 많은 양의 범용 연산을 병렬로 처리해, 처리 속도를 높였다.
▷ Dispatch Unit
본 논문은 SIMT(Single Instruction Multiple Thread) 구조의 GP-GPU에서 Warp Scheduler로부터 발행된 명령어를 Decoding할 때 해당 명령어의 정보를 모두 Decoding하는 기존의 방법과 다르게, Operand의 정보만 Decoding하는 Pre-Decoding 방법을 적용한 Dispatch Unit을 제안한다.
제안하는 Dispatch Unit은 명령어를 처리할 때 불필요한 Operand의 Load를 방지하고 레지스터의 부하를 줄일 수 있다.
▷ Operand Selection Unit
이 후 레지스터 뱅크 충돌을 방지하는 방법을 적용한 Operand Selection Unit을 설계하여, Dispatch Unit에서 전달받은 Operand의 정보들을 이용해 레지스터 뱅크 충돌을 방지하여 명령어 처리 성능을 향상시켰다.
2. Operand Selection Unit 설계
1. 명령어 Decoding 방법
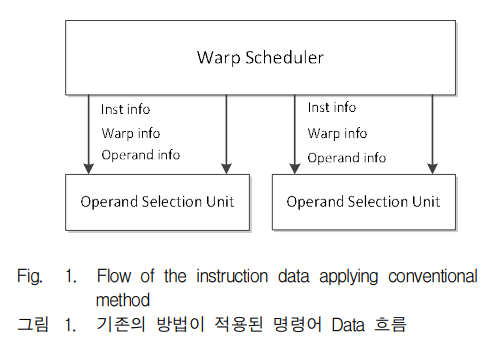

▷ 기존의 방법
기존의 명령어를 처리할 때 일반적인 Decoding 방법은 명령어의 타입, Operand의 종류, 상수 데이터 등을 Load한다.
Warp Schedular에서 발행된 명령어 Data에는 명령어의 정보, Warp의 정보, 두 개의 Operand 정보가 Operand Selection Unit에 전달되어진다.
- Problem: Warp Schedular로부터 발행된 모든 명령어의 모든 정보를 Decoding하여, Operand Selection Unit에서 SIMT 구조 GPGPU 스레드의 레지스터 접근 충돌 발생
Operand가 레지스터를 참조하지 않는 명령어일 경우에도 불필요한 Operand를 Load하게 되는 단점이 존재하는데, 이는 레지스터에 부하를 발생시킨다.
특히 SIMT 구조의 GP-GPU는 하나의 명령어를 다중 스레드로 처리하는데, 여러 개의 스레드가 동시에 하나의 레지스터에 접근하게 되면, 레지스터 접근 충돌이 발생하게 된다. 레지스터 접근 충돌이 발생하게 되면, 명령어를 처리하는데 소요되는 총 Clock Cycle이 증가되어, 처리 성능이 저하되는 단점이 존재한다.
▷ 제안하는 방법
- Solution: Dispatch Unit을 이용한 Pre-Decoding
- Warp Schedular에서 명령어 정보와 실행중인 Warp 정보가 Dispatch Unit에 전달된다.
- Dispatch Unit에서는 명령어가 가진 Operand가 레지스터를 참조하는지 확인하여, Operand Selection Unit에 Operand의 정보가 전달된다.
- Pre-Decoding을 통해 EXTIMM 명령을 지원한다. EXTIMM 명령의 경우, 확장된 상수(Extend immediate)를 처리하는 명령어다. 확장된 상수 명령어를 처리할 때 하위 27비트에 담긴 확장된 상수값을 Operand Selection Unit에 전달한다. 해당 명령어는 Operand를 사용하지 않는 경우이므로, Pre-Decoding 방법을 사용해 Opcode를 미리 확인하여 Operand Load를 방지한다.
2. Operand Selection Unit 설계


▷ 기존의 방법
Dispatch Unit에서 전달받은 Operand의 정보를 이용해 Pipeline 형태의 Operand Selection Unit에서 명령어 처리를 진행한다. 두 개의 Warp에서 각각 하나의 명령어, 총 2개의 명령어를 처리하기 위해 2개의 Operand Selection Unit으로 구성되어 있다.
- Problem: Operand를 Load할 때, 레지스터 뱅크 충돌 문제
그림 3의 (A)와 같이, 4개의 Operand가 모두 하나의 레지스터 뱅크에 존재하는 경우, 뱅크 충돌이 발생하게 되어 Pipeline Stall이 발생하게 된다. - Solution 1) FIFO Memory based Operand Selection Unit
레지스터 뱅크에 접근할 Operand Index를 FIFO에 저장한다. 이 후, FIFO에 저장되어 있는 순서대로 레지스터 뱅크에 접근하여 Operand를 Load하는 방법이다.
--> Problem: 뱅크 충돌이 발생하게 되는 경우, 많은 처리 Clock Cycle을 소모하게 된다. - Solution 2) Full Pipeline based Operand Selection Unit
한 Clock Cycle에 오직 하나의 Operand Index만 레지스터 뱅크에 접근하도록 설계하여 뱅크 충돌을 제거하는 방법이다. 뱅크 충돌이 발생하더라도 Full Pipeline 방법으로 설계되었기 때문에, 고정된 처리 Clock CYcle을 소모하게 된다.
--> Problem: 명령어에서 요구하는 Operand의 개수가 2개 이하인 경우에도 뱅크 충돌이 발생하는 경우와 같은 Clock Cycle을 소모하게 되어, 처리 속도가 늦어진다.
▷ 제안하는 방법

총 4개의 Operand 중 2개의 Operand를 우선적으로 레지스터 뱅크에서 Load한 후, 나머지 두 개의 Operand를 Load한다.
- FIFO Memory based Operand Selection Unit보다 처리 속도는 많이 느려지지 않지만, 추가적인 FIFO를 필요로 하지 않아 자원 소비량이 적다.
- Full Pipeline based Operand Selection Unit보다 Pipeline Stage가 줄어들어 처리 속도가 빨라지며, 마찬가지로 자원 소비량이 줄어들게 되어 자원 대비 처리 성능이 올라 처리 속도가 빨라진다.
3. 실험 결과

실험 비교 결과 사용된 자원 대비 처리 소요 Clock Cycle이 크게 차이가 나지 않는 것을 확인하였고, 본 논문에서 제안한 방법이 가장 높은 효율임을 확인할 수 있었다.
4. 결론
본 논문은 SIMT 기반의 GP-GPU에서 명령어를 Decoding하는 과정에서 불필요한 Operand Load를 방지하는 Pre-Decoding 방법을 적용한 Dispatch Unit과, 레지스터 뱅크 충돌을 방지하기 위한 Operand Selection Unit을 설계하였다.
본 논문에서 제안한 Pre-Decoding 방법을 적용한 Dispatch Unit과 레지스터 뱅크 충돌을 방지하기 위한 방법을 적용한 Operand Selection Unit을 기반으로 설계된 SIMT구조의 GP-GPU에서는 불필요한 연산과 레지스터 접근 및 레지스터 뱅크 충돌을 방지하여, 명령어 처리 속도가 향상되는 구조임을 증명하였다.
https://www.kci.go.kr/kciportal/ci/sereArticleSearch/ciSereArtiView.kci?sereArticleSearchBean.artiId=ART002035515
SIMT구조 GP-GPU의 명령어 처리 성능 향상을 위한 Dispatch Unit과 Operand Selection Unit설계
본 논문은 그래픽 처리 뿐 만 아니라 범용 연산의 가속화를 지원하기 위한 SIMT 구조 GP-GPU의 Dispatch Unit과 Operand Selection Unit을 제안한다. Warp Scheduler로부터 발행된 명령어에서 사용되는 Operand의 모
www.kci.go.kr
'논문' 카테고리의 다른 글
| 2차원 구조 대비 3차원 구조 GPU의 메모리 접근 효율성 분석 (0) | 2023.08.31 |
|---|---|
| GPU 공유 메모리 크기에 따른 최적화 기법 (0) | 2023.08.31 |
| GPU Register File의 Bank Conflict 분석 (0) | 2023.08.24 |
| GCN 아키텍쳐 상에서의 OpenCL을 이용한 GPGPU 성능향상 기법 연구 (0) | 2023.08.22 |
| GPU 컴퓨팅에서 빠른 데이터 전송을 위한 메모리 피닝 자동 관리 (0) | 2023.08.21 |


