Main Memory Supporting Caches

- 조건) 4-word block, 1-word-wide DRAM
▶ 1-word-wide memory
: 메모리에서 4-word block을 캐시로 읽어와야 하는데, 한번에 접근할 수 있는 메모리 크기는 1-word이다.
--> 메모리에 접근해서, 데이터를 전송하는 데에 4배의 시간이 더 걸린다. (miss penalty: 캐시 미스 패널티)
Increasing Memory Bandwidth
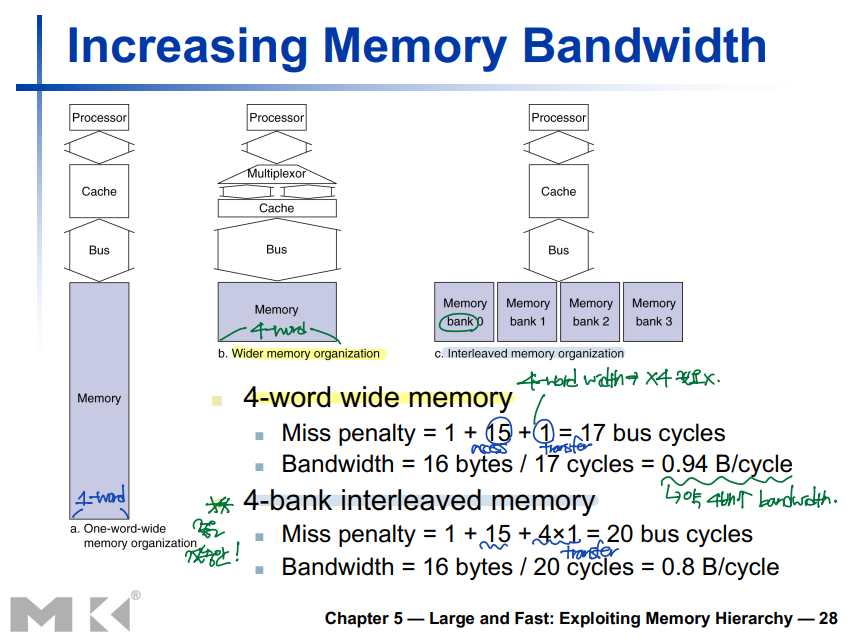
▶ 4-word-wide memory
: 메모리에서 4-word block을 캐시로 읽어와야 하는데, 한 번에 접근할 수 있는 메모리 크기는 4-word이다.
--> 한 번의 메모리 접근/전송으로 4-word block을 처리할 수 있다.
▶ Interleaved memory
: 메모리에서 4-word block을 캐시로 읽어와야 하는데, 한 번에 접근할 수 있는 메모리 크기는 4-word이지만, 한 번에 전송할 수 있는 양은 1-word이다.
--> 한 번의 메모리 접근, 4번의 전송으로 4-word block을 처리할 수 있다. (좋은 절충안!)
Measuring Cache Performance
- Cache hit --> 프로그램이 계속 진행된다. (program execution)
- Cache miss --> 캐시에 없는 데이터는 메모리에 있으므로, 메모리에 접근한다. (memory stall)
: 메모리에서 어떤 데이터를 찾아오려고 할 때,
- 캐시에 접근한다.
- 만약 cache hit --> 프로그램이 계속 진행되고, cache miss --> 진짜 메모리로 접근한다.
Cache Performance: Example
1) Actual CPI(Clock Cycle Per Instruction)
▶ Actual CPI = base CPI + I-cache miss cycles + D-cache miss cycles
: 하나의 instruction 당 필요한 clock cycle 수 --> cache miss가 적어지면, 줄어든다!
- Base CPI - base CPI가 작아지면, Actual CPI에서 cache miss(cache penalty)가 차지하는 비율이 늘어난다.

2) AMAT(Average Memory Access Time)
▶ AMAT(Average Memory Access Time) = Hit time + Miss rate * Miss penalty
: 평균 메모리 접근 시간 --> cache miss가 적어지면, 줄어든다!

▷ Cache Performance!
: 평균 메모리 접근 시간(AMAT)이 줄어들면, 메모리 접근 instruction에 필요한 clock cycle 수도 줄어들 것이기 때문에, Actual CPI가 작아진다. (메모리 접근에는 많은 clock cycle이 소모된다.)
--> 평균 메모리 접근 시간을 줄이는 것이 중요하다. --> Cache miss를 줄이는 것이 중요하다!
Performance Summary
: Cache miss가 발생하면, 메모리 접근 시에 많은 시간 즉, 많은 clock cycle이 소요된다.
--> CPI(Clock Cycle Per Instruction)이 늘어나고, 성능이 나빠진다. --> Cache miss를 줄이는 것이 중요하다!
Associative Caches
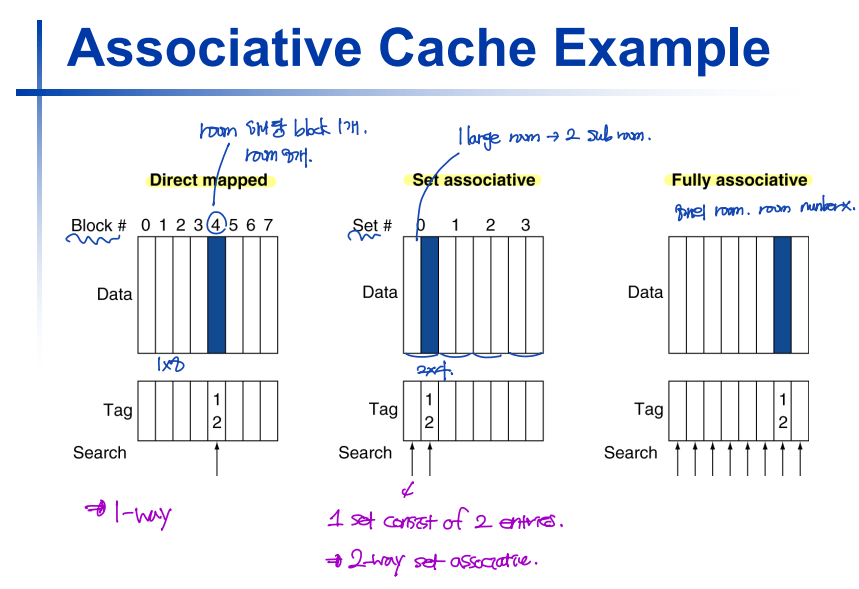
- Direct mapped cache: 하나의 cache index 당 room이 1개이다.
- Set associative cache: 하나의 cache index 당 room(sub-room)이 여러개다.
- Fully associative cache: Cache index는 존재하지 않고, 모든 room에는 index가 없다. --> Everyone share the room!
Spectrum of Associativity

Associativity: Example
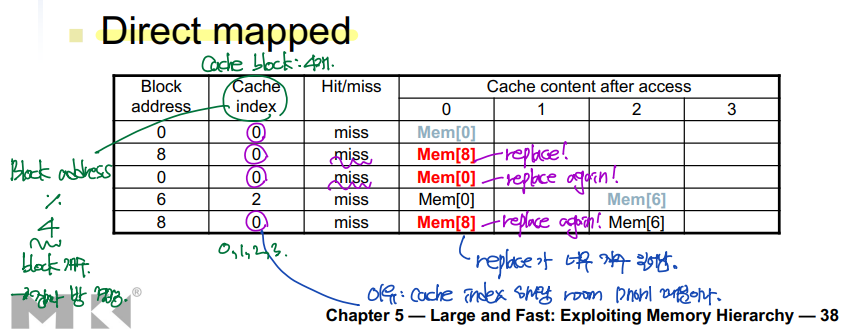
: 하나의 cache index 당 room이 1개이다.
--> Cache miss로 인한 replacement가 너무 자주 일어난다.
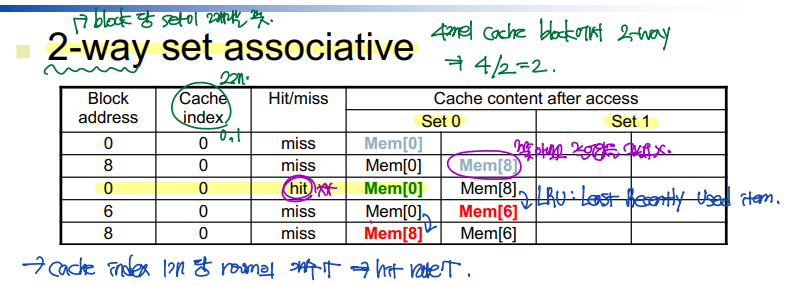
: 하나의 cache index 당 room이 2개다.
--> Cache hit 비율 ↑
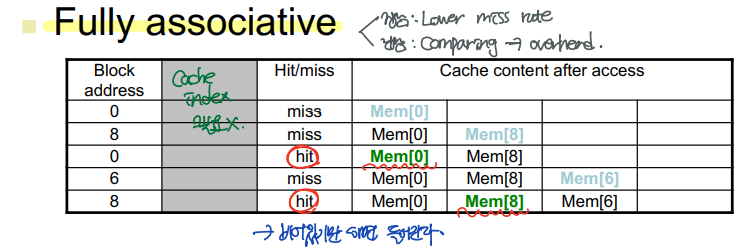
: Room에는 cache index가 없고, 모든 room을 모두가 공유한다.
--> 캐시가 비어 있기만 하면, 그 안에 값을 쓴다.
--> Cache hit 비율 ↑ ↑ ↑
How Much Associativity?
▷ Trade off:
Sub-room 개수가 많으면, 극단적으로 fully associative cache이면, cache hit 비율이 높아진다.
하지만, 하나의 cache index에 많은 정보가 저장되어 있기 때문에, searching time으로 인한 오버헤드가 발생한다.
Set Associative Cache Organization: Example
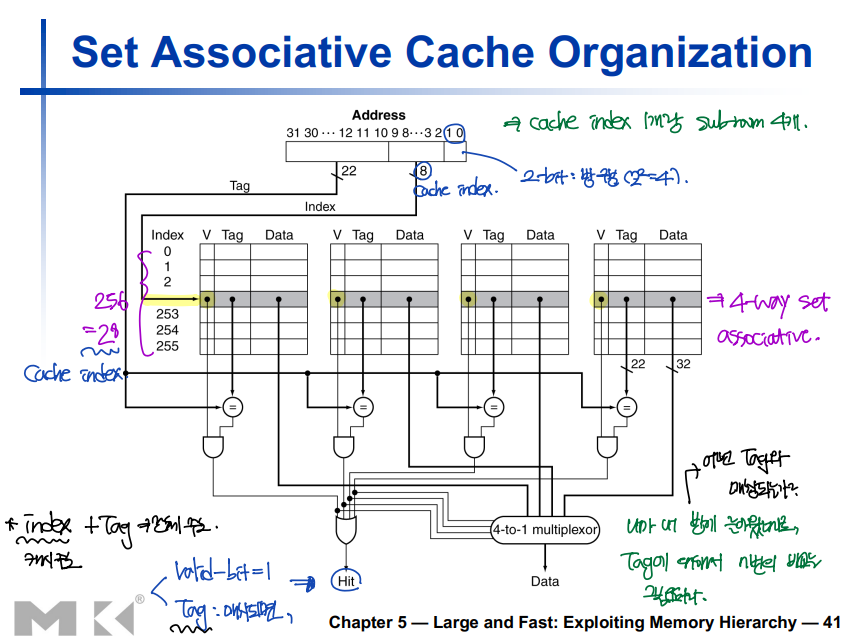
Replacement Policy
▶ Direct mapped: no choice (그냥 다 대체되어야 함)
▶ Set associative:
- LRU(Least-recently used): 가장 예전에 사용된 것을 지운다.
- Random <-- LRU overhead
Multi-level Caches
- L1 cache
- L2 cache
- L3 cache
Multi-level Cache: Example


Multi-level Cache Considerations
▶ L1 cache
- 목적: 빠른 접근!
--> Small number of blocks
--> Direct mapped cache (하나의 cache index 내에서의 비교 시간이 없다.)
▶ L2 cache
- 목적: 메모리로 가는 것만은 피하자. (Cache hit rate이 가장 중요!)
--> Large number of blocks (최대한 많이 저장한다.)
--> Many sub-rooms --> Cache hit rate ↑
Interactions with Software
▷ Misses depend on memory access patterns.
- Algorithm behavior
- Compiler optimization for memory access
출처: 이화여자대학교 이형준교수님 컴퓨터구조
'Computer Architecture > 컴퓨터구조[01]' 카테고리의 다른 글
| [혼자 공부하는 운영체제] 14-2. 페이징을 통한 가상 메모리 관리 (1) | 2023.11.28 |
|---|---|
| [혼자 공부하는 운영체제] 14-1. 연속 메모리 할당 (0) | 2023.11.27 |
| [컴퓨터구조] 1115 (0) | 2023.11.15 |
| [컴퓨터구조] 1113 (2) Ch5. Cache & Memory Systems (0) | 2023.11.13 |
| [컴퓨터구조] 1113 (1) (0) | 2023.11.13 |



