Cache Example

- Index: 몇 번째 cache block인지 결정한다. (마지막 3-bit)
- V: 해당 cache block에 데이터가 있는지 표시한다.
- Tag: 해당 cache block에 있는, 어떤 데이터인지 구분한다. (전체 주소 = Tag_Index)
- Data: 메모리의 (Tag_Index) 주소에서 가져온 1 word(4 bytes) 데이터
Address Subdivision
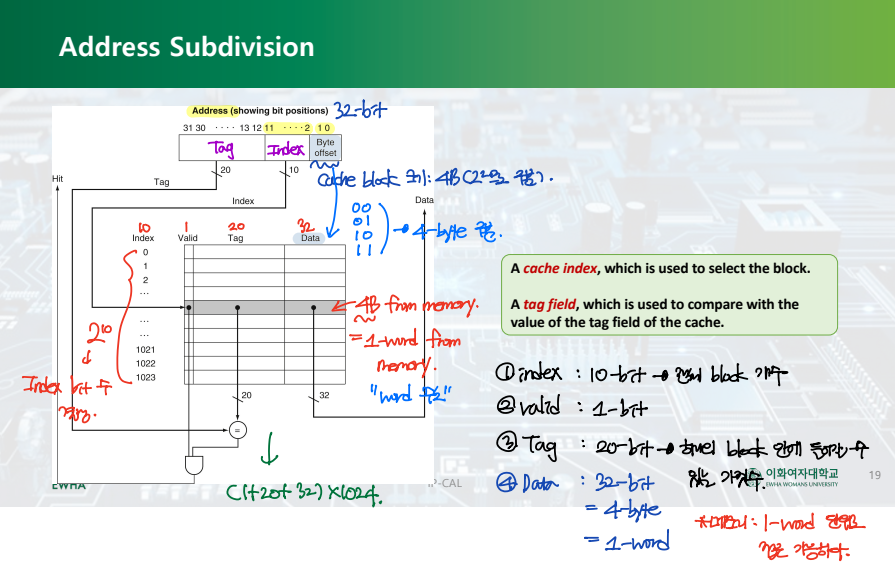
- Index (10 bits): "몇 번째 cache block인가?"
- Valid (1 bit): "이 cache block 안에는 데이터가 들어있는가?"
- Tag (20 bits): "이 cache block 안에는 정확히 어떤 데이터가 들어있는가?"
- Data (32 bits = 4 bytes = 1 word) --> Byte offset: 4 bytes 데이터를 구분한다.
**메모리: word 주소 --> 4 bytes
- 메모리는 4 bytes 단위로 접근 가능하다.
Example: Larger Block Size
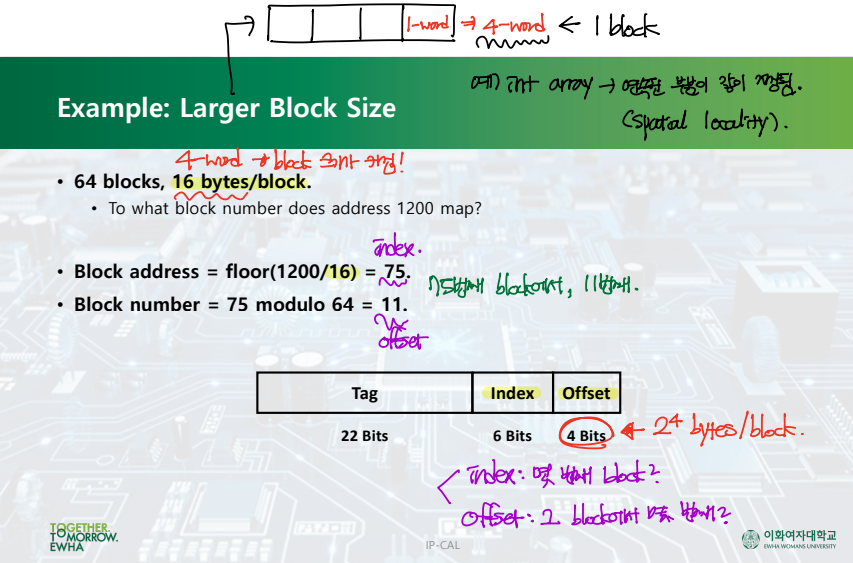
▷ 하나의 block의 크기가 4 bytes가 아닌, 16 bytes일 수 있다!
- Block address = 주소값/block 크기 --> "해당 주소는 몇 번째 block에 속하는가?"
- Block number = "진짜 몇 번째 block에 속하는가? 총 block의 개수는 64개이기 때문에 75번째 block은 없다."
▶ Tag: 나머지 주소
▶ Index: cache block 주소 --> "몇 번째 cache block에 속하는가?"
▶ Offset: 하나의 block 크기가 2^4 bytes다. --> "그 cache block에서 몇 번째인가?" (4 bytes 단위로 접근하므로 0, 1, 2, 3번째까지 있음)
Large Blocks
- 장점: 하나의 block 크기가 크다. = Hit ratio ↑
- 단점: 하나의 block 크기가 크면, 전체 block 개수는 줄어들 수밖에 없다. = miss penalty
▶ Miss panelty
: 메모리에서 cache block에 fetch하는 시간 + cache block에 load하는 시간
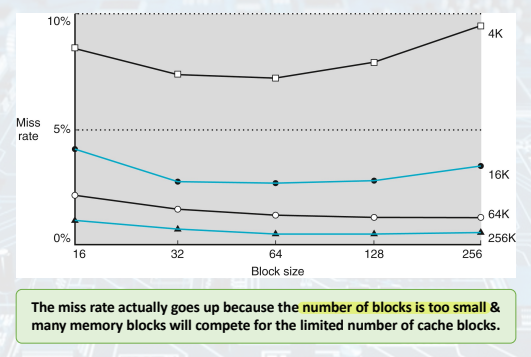
- 총 block의 개수가 적기 때문에, conflict가 자주 발생하여 캐시에서 자주 쫓겨나게 된다. 결국 miss ratio가 높아짐.
Miss Rate vs. Block Size
Handling Cache Misses
▶ 파이프라인
: IF --> ID --> EX --> MEM --> WB
- IF: Instruction memory --> I-cache
- MEM: Data memory --> D-cache
Handling Writes
▶ Write: sw처럼 메모리에 값을 써야하는 상황
- lw: 메모리 --> 레지스터
=> 캐시 --> (메모리) --> 레지스터: 캐시에서 read - sw: 레지스터 --> 메모리
=> 레지스터 --> 캐시 --> (메모리): 캐시에 write
▶ Write-through
: 캐시, 메모리에 둘 다 쓴다.
- Write buffer를 두어, write buffer가 꽉 차면, 메모리에 쓴다.
▶ Write-back
: 일단 캐시에만 쓴다. 해당 데이터가 캐시에서 쫓겨날 때, 메모리에도 쓴다.
--> 메모리 접근 횟수가 줄어든다!
출처: 이화여자대학교 윤명국교수님 컴퓨터구조
'Computer Architecture > 컴퓨터구조[05]' 카테고리의 다른 글
| [CA] Lecture #26 (1) (0) | 2023.12.01 |
|---|---|
| [CA] Lecture #25 (1) | 2023.11.28 |
| [CA] Lecture #23 - Ch5: Large and Fast: Exploiting Memory Hierarchy (0) | 2023.11.21 |
| 파이프라이닝(Pipelining)과 비순차적 명령어 처리(Out-of-order execution) (3) | 2023.11.20 |
| [CA] Lecture #22 (1) | 2023.11.17 |



