컴퓨터구조 수업시간에 교수님께서 파이프라이닝으로 인한 hazard 문제와 그 해결책들에 대해 설명해 주시면서 out-of-order core 이야기를 하셨는데요,,, 관심이 있으면 찾아보라고 하셔서 한번 찾아보았습니당. 세상에는 알아가야 될 게 정말 많네요... ㅎㅎ
- 비순차적 명령어 처리(out-of-order execution)
- 비순차적 명령어 코어(out-of-order core)
먼저, 비순차적 명령어 처리에 대해 이해하기 위해서는 컴퓨터의 CPU에서 명령어들을 처리하는 과정에 대한 이해가 필요하다.
간단하게 요약하면:
컴퓨터는 명령어를 처리한다. 그리고 이 명령어들을 좀 더 빠르게 처리하기 위해 어떤 기법(파이프라이닝; pipelining)을 이용한다. 그런데 이 기법을 이용하면, 명령어들 간의 의존성 때문에 문제(hazard)가 발생할 수 있다.
따라서 이 문제를 해결하기 위해 하드웨어적 해결책을 마련한다. (Forwarding을 위한 pipeline register, Branch prediction을 위한 branch predictor) 하지만 이러한 하드웨어적 해결책은 비용이 많이 든다.
그래서 이러한 문제를 해결하기 위해, 소프트웨어적 해결책을 마련한다. 그 소프트웨어적 해결책이 바로: 비순차적 명령어 처리(out-of-order execution)이다.
먼저, 기본적인 문제들(hazard)과 그에 대한 해결책에 대해 알아보도록 하자.
CPU에서는 다양한 명령어(instruction)들을 처리한다.
이때, 이 명령어 처리 속도를 높이기 위해 파이프라이닝(pipelining) 기법을 이용한다. 파이프라이닝을 하기 위해서는,
- 하나의 명령어를 IF, ID, EX, MEM, WB의 5단계로 나눈다.
- 한 번의 clock cycle time동안, 여러 명령어들을 동시에 처리한다. 이때 각각의 명령어들은 서로 다른 단계에 속해 있기 때문에, 동시에 처리될 수 있다.
그러나 이때 문제가 발생한다.
앞선 명령어의 어떤 단계까지가 끝나야, 뒤 명령어 처리가 가능할 수 있다. 즉, 어떤 명령어들 사이에 의존성이 있을 수 있다. 우리는 이를 hazard라고 한다.
▶ Hazard의 종류:
- Structural hazard
- Data hazard
- Control hazard
Structural Hazard
Memory hazard: IF and MEM at the SAME time!!!
먼저 structural hazard는 IF와 MEM 단계가 같은 clock cycle time 내에서 일어날 때 발생한다.
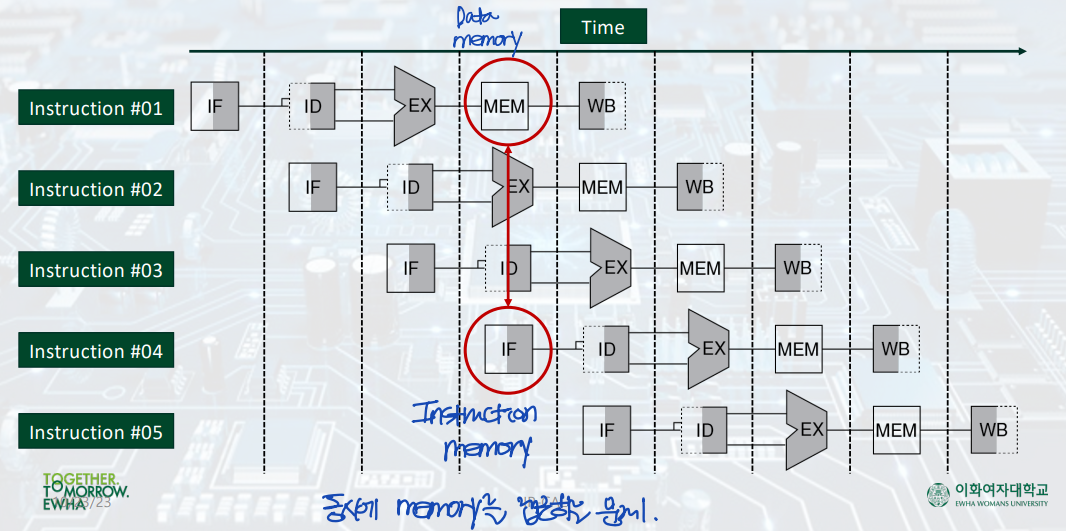
IF(Instruction Fetch and increase the PC value) 단계에서는, 메모리에 접근하여, 해당 명령어와 명령어 내의 레지스터에 접근할 수 있도록 하는 주소값을 얻어온다. MEM(read/write from/to Memory) 단계에서는, 메모리에 접근하여 메모리에서 어떤 값을 읽거나(lw instruction), 메모리에 어떤 값을 쓴다(sw instruction).
그런데 만약 이때, IF 단계에서 어떤 값을 읽는 과정이 MEM 단계에서 어떤 값을 쓰는 과정보다 먼저 일어나면 어떻게 될까? IF 단계에서 읽어야하는 값이 아닌 다른 값을 읽게 될 수 있다.
▷ 해결책: "Harvard Architecture" - instruction memory, data memory
: IF 단계에서는 instruction memory에 접근하도록 하고, MEM 단계에서는 data memory에 접근하도록 하여, 즉 메모리를 두 개로 나누어, 이 문제를 해결한다.
Register hazard: ID and WB at the SAME time!!!
structural hazard는 ID와 WB 단계가 같은 clock cycle time 내에서 일어날 때에도 발생한다.
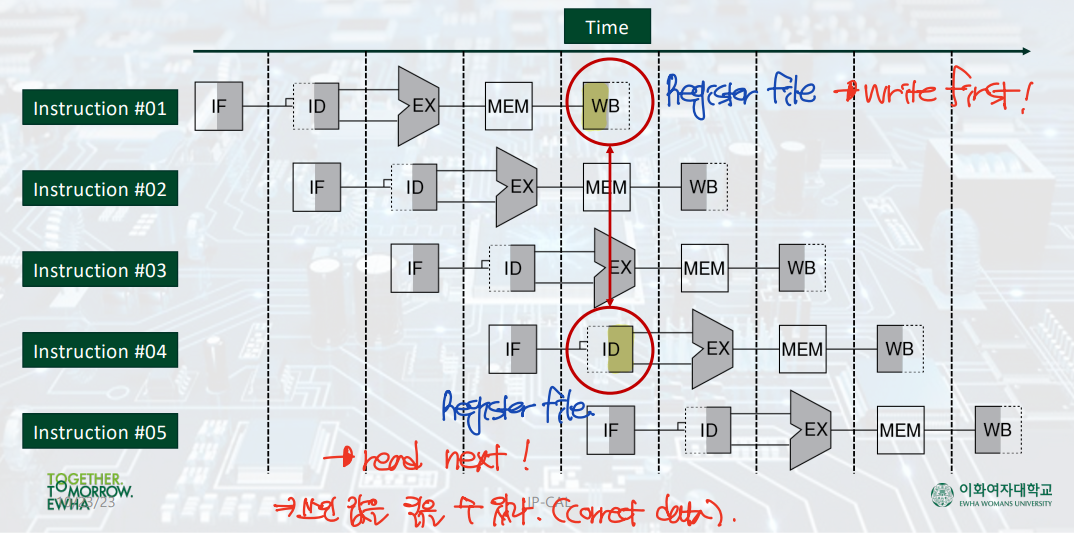
ID(Instruction Decode) 단계에서는, 레지스터 파일에 접근하여, 명령어의 레지스터 번호에 대한 데이터 값을 읽는다.
WB(Write Back) 단계에서는, 레지스터 파일에 접근하여, 명령어 처리 결과값을 다시 레지스터에 저장한다.
그런데 만약 이때, WB 단계에서 어떤 값을 레지스터에 쓰기 전에 ID 단계에서 레지스터 값을 읽어버리게 되면 어떤 일이 일어날까? ID 단계에서는 원래 읽어야했던 값이 아닌 다른 값을 읽게 될 수 있다.
▷ 해결책: ID와 WB이 동시에 일어난다면, WB 먼저, ID 나중에 일어나도록 한다.
--> 같은 레지스터 파일이어도 WB 단계에서 결과값을 쓴 뒤에 ID 단계에서 그 값을 읽기 때문에, 문제가 발생하지 않는다.
Data Hazard
Structural hazard는 ID와 WB 단계가 동시에 일어날 때, 레지스터 파일에 동시에 접근하는 문제로 인해 발생하였다. 따라서 이때, 이러한 동시 접근 문제를 해결하기 위해, WB 단계의 write가 먼저 일어난 후, ID 단계의 read가 될 수 있도록 하였다.
하지만 만약, 두 개의 명령어가 순차적으로 일어나서, 첫 번째 명령어가 WB 단계로 가기 전에 두 번째 명령어의 ID 단계가 먼저 일어난다면 어떻게 해야 할까? WB과 ID의 동시 발생은 structural hazard에서 해결하였으나, WB이 시작도 되기 전의 clock cycle 단계에서 ID가 발생한다면, 그것은 data hazard이다.
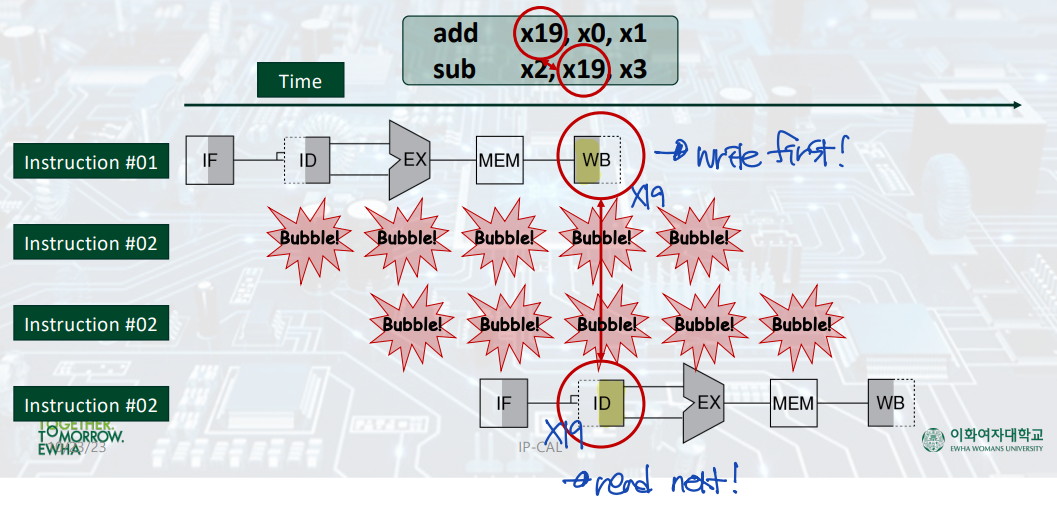
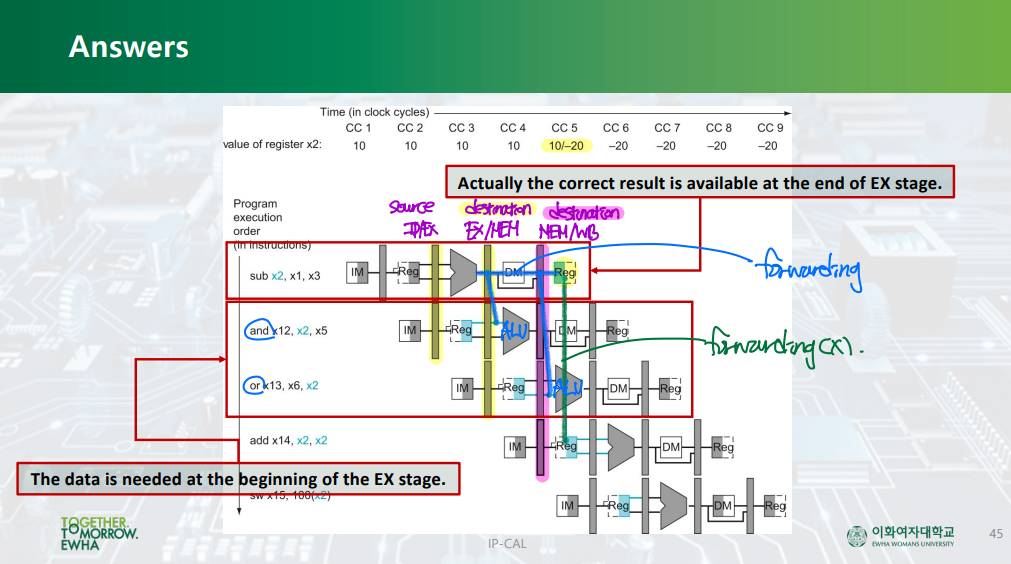
▷ 해결책: Pipeline register를 이용하는 Forwarding.
: 파이프라인 레지스터를 이용하여, 앞선 명령어의 결과를 WB 단계 이전에 두 번째 명령어에서 그를 필요로 하는 구간으로 끌고온다.
--> 그럼에도 불구하고 STALL이 발생할 수는 있으나, 어느정도 문제가 해결된다.
Control Hazard
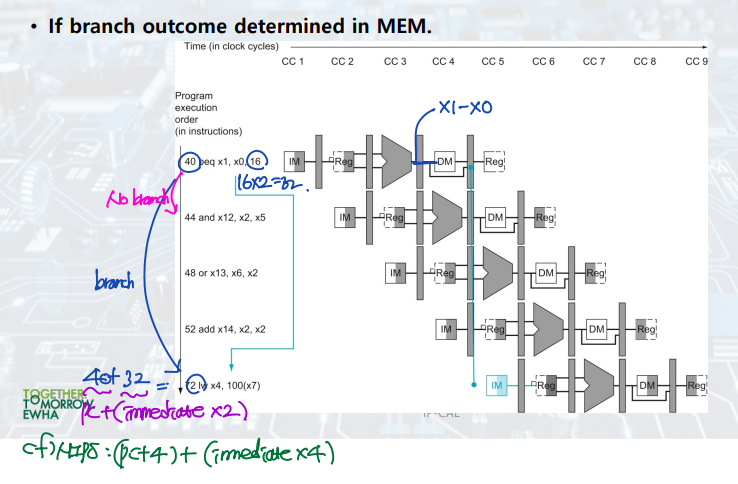
Branch 명령어의 경우, 명령어의 레지스터 값들을 비교하여 branch 여부를 결정한다. 따라서 branch 여부가 결정되지 않은 상태에서는 그 다음에 어떤 명령어를 실행해야 할 지 알 수 없기 때문에, PC 값을 결정할 수 없다.
MIPS ISA의 경우,
만약 branch를 하지 않는다면: PC <- PC+4 + immediate*4
만약 branch를 한다면: PC <- PC+4
로 PC 값이 변하게 된다.
beq의 경우, branch 여부를 결정하기 위해서는 branch 명령어가 EX 단계에서 subtraction 연산을 마쳐야 한다. 따라서 EX 단계 이전에는 branch 여부를 알 수 없고, IF 단계에서 PC 값을 결정할 수 없다.
- 문제는 EX 단계와 IF 단계에서 일어난다.
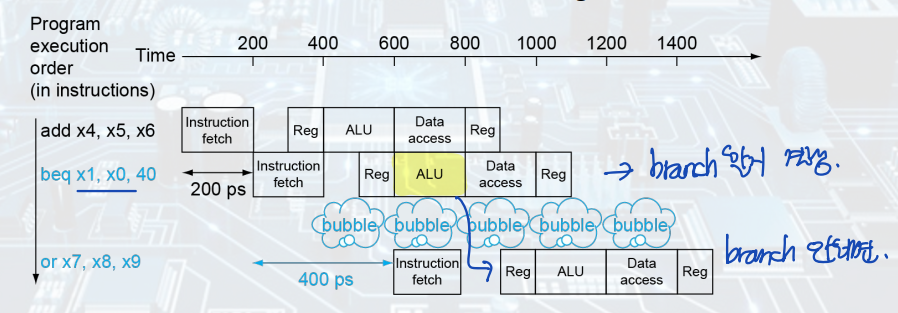
▷ 해결책 1) Register comparator
: Branch 여부를 beq 명령어의 ID 단계 이후에 판단할 수 있도록 하기 위해, register comparator를 이용한다. 이는 beq 여부를 결정하기 위한 레지스터 값의 비교를 ID 단계에서 수행하고, 그 결과를 IF 단계의 PC를 결정하기 위한 MUX에 전달하는 역할을 한다. 그러나 이러한 방법에는 1 STALL은 불가피하게 발생하게 된다.
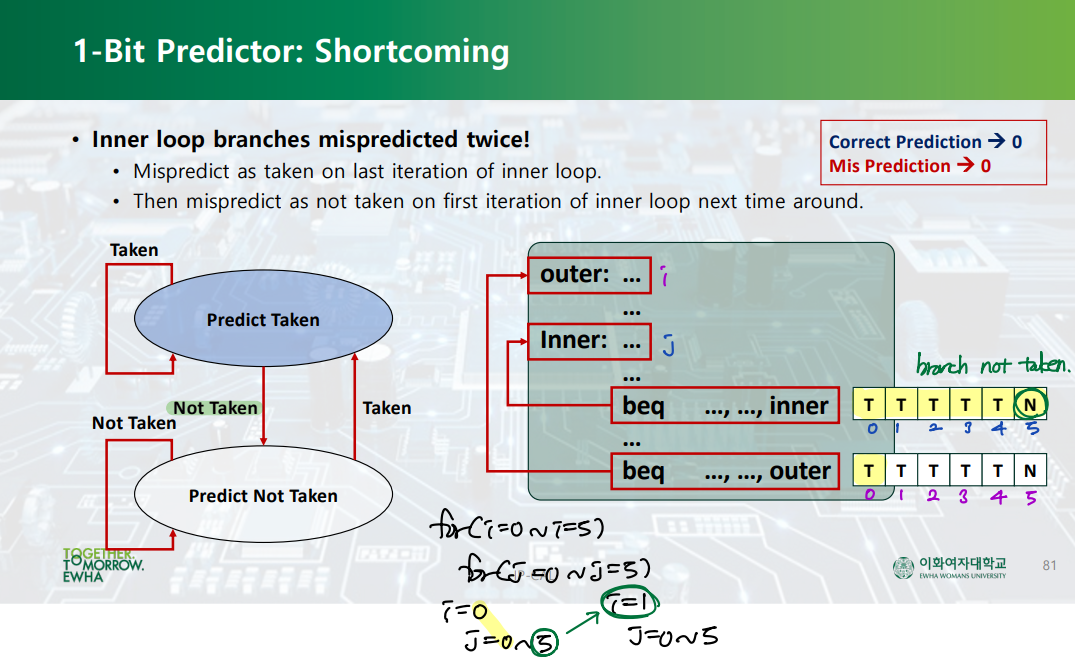
▷ 해결책 2) Branch prediction
: Branch predictor를 통해 branch 여부를 예측한다. 만약 예측이 맞을 경우 STALL이 발생하지 않고, 예측이 틀릴 경우 1 STALL이 발생한다.
정리하자면, 명령어 처리 시간을 감소시키기 위한 방법인 pipelining은 3가지의 hazard를 야기하였다.
- Structural hazard:
1) memory hazard --> instruction memory, data memory
2) register hazard --> write first(WB), read next(ID). - Data hazard: write first(WB), read next(ID)가 있음에도 불구하고 발생하는 명령어들 간 의존성 문제
--> Forwarding by. pipeline register - Control hazard: PC값을 결정하기 위한 branch 여부 판단 문제
--> 1) Register comparator
--> 2) Branch prediction
이 중, data hazard를 해결하기 위한 forwarding과 control hazard를 해결하기 위한 branch prediction은 굉장히 중요하다! 아래 그림을 통해 자세히 살펴보자.
(자료 출처: 이화여자대학교 윤명국교수님 컴퓨터구조)
Data Hazard --> Forwarding by. pipeline register
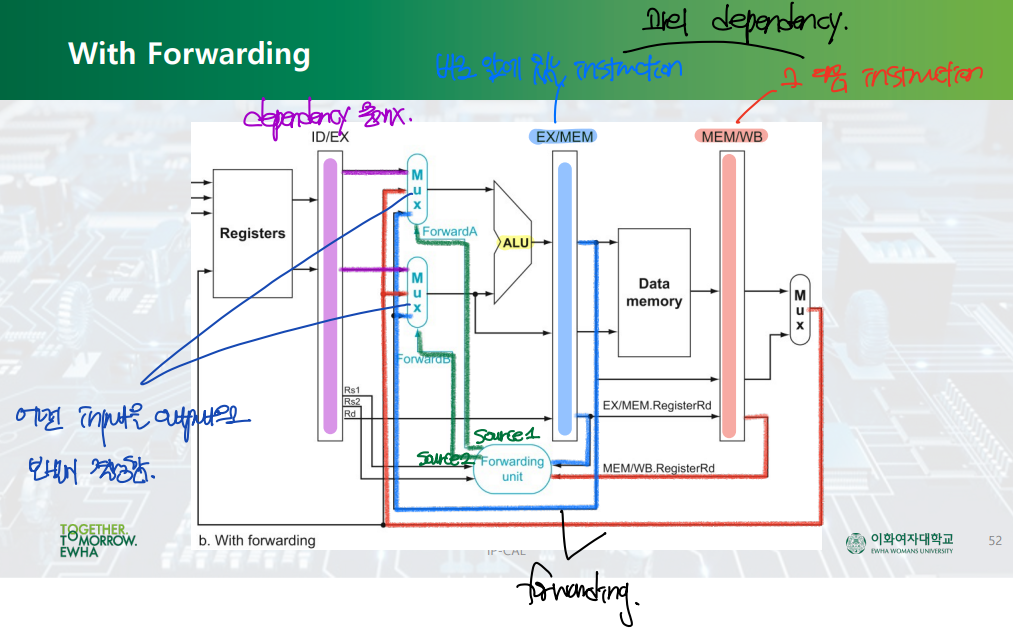
Control Hazard --> Branch Prediction by. branch predictor
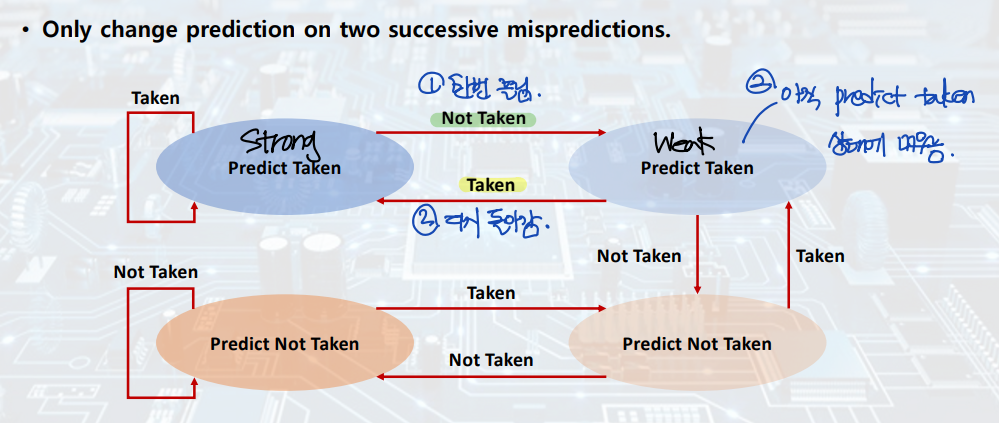
지금까지 파이프라이닝으로 인한 세 가지 hazard와 그를 해결하기 위한 하드웨어적 해결책들을 살펴보았다.
자, 이제 소프트웨어적 해결책, 비순차적 명령어 처리(out-of-order execution)에 대해 알아보자!
비순차적 명령어 처리(out-of-order execution)
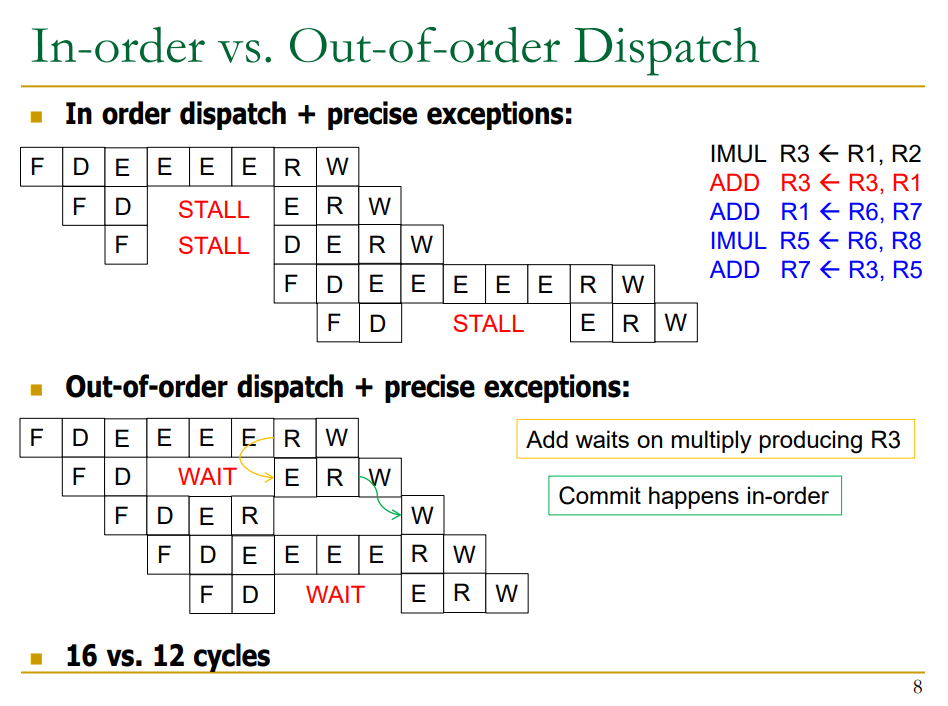
비순차적 명령어 처리에 대해 간단하게 말하면, 명령어들의 순서를 바꿔서 의존적인 명령어들 사이의 간격을 벌리고, 이를 통해 그들 사이의 의존성 문제로 인한 STALL을 없애는 것이다.
▶ 명령어들의 순서를 바꿔서 비순차적 명령어 처리(out-of-order execution)을 하기 위해서는,
- 명령어 사이의 의존 관계를 판단한다. (의존적인 명령어 == operand가 준비되지 않은 명령어)
- Register Renaming: 현재 레지스터 설정 상태 하에서는 의존적이지만, 레지스터 번호를 변경하면 의존성이 사라지는 '가짜 의존성'을 제거한다. (by. 물리 레지스터 파일, 물리 레지스터 파일과 논리 레지스터 파일을 매핑해주는 RAT)
- Reservation Station: 명령어 사이의 의존성으로 인해 아직 operand가 준비되지 않아서 뒤로 보내져야 하는 명령어는 Reservation Station으로 보낸다. Operand가 준비되는 대로 Reservation Station에서 꺼내서 명령어를 실행한다.
- Reorder Buffer: 명령어 처리는 비순차적으로 하더라도, 프로그래머에게 보내는 결과는 순차적이어야 한다. 따라서 실행이 끝난 명령어들은 Reorder Buffer에 저장을 해뒀다가, 순차적으로 내보낸다.
1. 이러한 과정은 '명령어 윈도우' 내에서 진행된다. 즉 약 100여개(시스템마다 다름) 정도의 명령어 범위 내에서 의존성 검사를 하는 것이다.
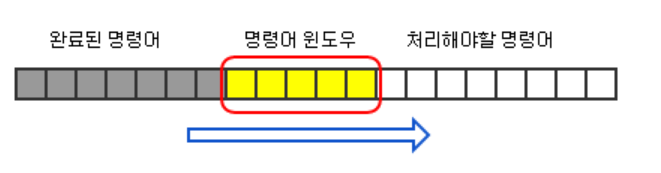
명령어가 명령어 윈도우로 들어오면, 그 명령어의 의존 관계를 판단하고, '가짜 의존성'을 제거하고, 만약 의존적이라면 Reservation Station으로 보내고, 의존적이지 않다면 곧바로 실행하여 그 결과를 Reorder Buffer에 저장해둔다.
2. 가짜 의존성은 어떻게 제거될까? 레지스터 번호를 그냥 무작정 바꾼다면, 뒤에서 뜻하지 않은 의존성이 생길 수 있다.
따라서 '진짜 레지스터 번호(논리 레지스터 파일; Architecture Register File - ARF)'은 변경하지 않고, 진짜 레지스터 번호를 '임시 레지스터 번호(물리 레지스터 파일; Physical Register File - PRF)'을 설정하여 내부에서 해당 명령어 처리를 하는 동안에는 물리 레지스터 번호를 이용했다가, 외부에 내보낼 때는 논리 레지스터 번호로 바꾼다. 이렇게 하면 '가짜 의존성'으로 인한 STALL은 발생하지 않게 된다.
이때 논리 레지스터와 물리 레지스터의 매핑 정보를 유지하는 장소를 RAT(Register Alias Table)이라고 한다.
3. 가짜 의존성을 제거하고 나서도, 의존 관계로 인해 operand가 준비되지 않아, 처리가 불가능한 명령어들은 Reservation Station(Queue)으로 보낸다. Reservation Station에 보내진 명령어는,
- Operand가 준비되면, --> Wake-up
- 이제 실행하면 되는데, 놀고 있는 실행장치(Function unit) 어떤거야? --> Select
Wake-up 작업은 어떤 선행 연산이 끝나서 operand가 준비되었는데, Reservation Station에 있는 명령어 중, 어떤 명령어가 해당 operand를 필요로 하는지 찾아서, 그 명령어를 꺼내오는 작업을 의미한다.
- 어떤 명령어가 해당 operand를 필요로 하는지 찾기 위해서는, 매번 Reservation Station에 있는 명령어들이 필요로 하는 operand를 모두 체크한다. (병목지점!)
Q. 명령어 의존 관계 판단할 때, 어떤 operand가 필요한지도 알아야 할 텐데... 이때 어떤 operand가 필요한지를 알아서 Reservation Station에 있는 명령어에 표시를 해 두면, 병목현상이 해결되지 않을까?
A. 다양한 방법들이 있음!!!
Select 작업은 (실행 가능한 명령어 수 < 실행장치 수) 일 때, 실행장치의 할당을 스케줄링하는 것을 말한다.
이 부분 역시, 실행 가능한 명령어 수보다 실행장치 수가 훨씬 적을 경우, 병목지점!
결국, 이러한 Reservation Station이 존재하기 때문에, 현재 실행 불가능한 명령어들이 머물 수 있는 Queue가 생기고, operand가 준비되는 대로 비순차적 명령어 실행이 가능해진다.
이렇게 operand의 준비 상태에 따라 동적으로 스케줄링하는 알고리즘이 바로 토마슐로(Tomasulo) 알고리즘이다.
4. 명령어의 처리는 비순차적으로 하더라도, 프로그래머에게는 프로그래머가 원하는 순서대로 결과를 보여주어야 한다.
따라서 실행 완료된 명령어들은 일단 Reorder Buffer에 모아두었다가, 원래의 프로그램 순서대로 차례차례(in-order) 내보낸다.
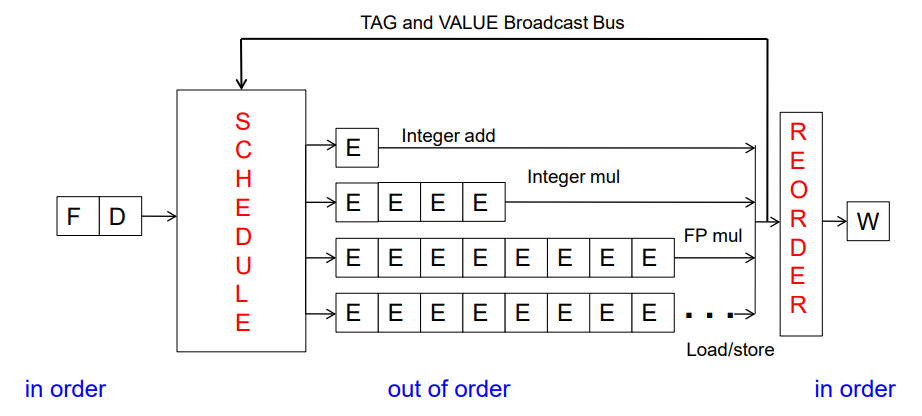
Reorder Buffer에 처음 명령어 순서대로 명령어들을 저장해야 하기 때문에, 의존성 검사가 완료된 명령어는, Reservation Station으로 보내질 지 결정되는 과정에서 Reorder Buffer에도 동시에 보내져서 entry를 할당받는다. 이렇게 명령어들에 대한 entry를 일단 Reorder Buffer에 넣어두고, 실행이 완료되면 그 값과 실행 완료 여부도 Reorder Buffer에 저장하여, 실행 완료된 명령어들을 내보낼 수 있게 한다.
비순차적 명령어 실행(out-of-order execution)에 필요한 핵심 기술 세 가지에 대해 알아보았다.
- Register renaming: 가짜 의존성 제거
- Reservation buffer: Operand가 준비되지 않은 명령어 저장하기 위한 queue
- Reorder buffer: 원래의 명령어 순서대로 내보내기 위한 queue
그러나 이 세 가지 기술에 하나가 더 추가되어야 하는데, 바로 메모리 연산을 위한 Load-Store Queue이다.
- lw $t0, 4($s0): MEM 단계에서 메모리에 저장된 값을 읽어서, WB 단계에서 레지스터에 쓴다.
- sw $t1, 4($s1): MEM 단계에서 레지스터에 저장된 값을 메모리에 쓴다.
▶ lw 명령어
- lw 명령어 실행에서 발생할 수 있는 명령어 의존성: $s0값에 따라 몇 번지 메모리에서 데이터 값을 읽어와야 할 지가 달라진다.
- lw 명령어 실행 이후에 발생할 수 있는 명령어 의존성: 메모리에서 어떤 값을 읽어와서 $t0에 어떤 값이 저장되는가?
--> 레지스터 값이 바뀌기 때문에, 어떤 명령어에든지 의존성을 유발할 수 있다.
▶ sw 명령어
- sw 명령어 실행에서 발생할 수 있는 명령어 의존성: $s1값에 따라 몇 번지 메모리에 레지스터 데이터를 써야 할 지가 달라진다.
- sw 명령어 실행 이후에 발생할 수 있는 명령어 의존성: 해당 메모리 주소에 어떤 값을 썼는가?
--> 메모리에 저장된 값이 바뀌기 때문에, lw 명령어에 의존성을 유발할 수 있다.

메모리 연산(lw, sw)은 MEM 단계에서 메모리(또는 cache)에 접근해야 하는 명령어이므로, 메모리 의존성을 띠고 있다고 말한다. 이때, 메모리 연산은 굉장히 느리기 때문에, 이러한 메모리 연산에도 병렬성을 발휘할 수 있다면, 성능에 큰 영향을 미치게 된다.
▶ Load-Store Queue
Reorder buffer의 경우, 명령어가 Reservation buffer로 보내질 지 결정되는 것과 동시에, 해당 명령어에 대한 entry가 생성된다. Load-Store queue도 이와 마찬가지로, 이 시점에 load/store 명령어에 대한 entry를 생성한다. 따라서 Load-Store queue에는 load/store 명령어가 순차적으로 쌓이게 된다.
--> 처리된 load/store 명령에 대한 결과:
- lw: 레지스터 값
- sw: 메모리에 저장된 값
처리된 load/store 명령에 대한 결과를 Load-Store queue에 저장해둔다.
lw 연산은 레지스터 값을 변경하기 때문에 그 뒤에 나오는 어떤 명령어에든지 의존성을 유발할 수 있고, sw 연산은 메모리에 쓰인 값을 변경하기 때문에 그 뒤에 나오는 lw 명령어에 의존성을 유발할 수 있어요.
lw/sw의 공통점은 MEM 단계가 꼭 필요하다는건데, 이 단계에서는 메모리(또는 캐시)에 접근하기 때문에 시간이 오래 걸려요.
lw/sw 명령어와 의존관계에 있으면 골치가 아프겠어요. (오래 걸리니까)
그래서 해결책은? Load-Store Queue에 lw/sw 명령어에 대한 결과만 저장을 해 둬요.
<--이게 왜 해결책이 되는지 이해가 안 간다...
연산 결과 operand를 Load-Store Queue에 저장하든, Reorder Buffer에 저장하든 어쨌든 연산이 끝나야 저장되는거니까 시간 오래걸리는건 똑같지 않나?
아니 그리고 lw는 레지스터 값 바꾸는거고, sw는 메모리에 저장된 값 바꾸는건데, 똑같은 큐에 저장할 수 있나? sw 다음에 lw 나와서 의존 관계 생기면, lw에서 메모리에 접근 안 하고 캐시에 접근해서 해결할 수 있게, sw에서 바뀌었던 메모리에 저장된 값을 캐시에 저장해둬야 될 거 같고... lw는 레지스터 값 바꾸는 거니까 다른 명령어들이랑 아무 차이 없고 그니까 그냥 Reorder Buffer에 저장해 둬도 될 거 같고...
Load-Store Queue가 필요한 이유가, lw/sw 연산 다음에 생기는 의존성 문제 때문인건 알겠는데, 그걸 뭐 어떻게 해결한다는건지 이해가 안 감... 뭔가 캐시랑 연관이 있다는거 같은데...
I'll be back... :')
출처:
http://cloudrain21.com/out-of-order-processor-pipeline-1
http://cloudrain21.com/out-of-order-processor-pipeline-2
'Computer Architecture > 컴퓨터구조[05]' 카테고리의 다른 글
| [CA] Lecture #24 (0) | 2023.11.23 |
|---|---|
| [CA] Lecture #23 - Ch5: Large and Fast: Exploiting Memory Hierarchy (0) | 2023.11.21 |
| [CA] Lecture #22 (1) | 2023.11.17 |
| [CA] Lecture #21 (1) | 2023.11.15 |
| [CA] Lecture #20 (1) | 2023.11.14 |



