Abstract
▶ STT-MRAM(Spin-transfer torque magnetic random-access memory)
: STT-MRAM is an emerging nonvolatile(비휘발성의) memory technology that has been received significant attention over SRAM. One compelling(주목할만한) use cas is to employ STT-MRAM as a graphics processing unit (GPU) register file (RF) to reduce its massive energy consumption.
- Problem 1) The problem of STT-MRAM
: One critical challenge is STT-MRAM has longer access latency and higher dynamic power consumption than SRAM. - Solution 1)
: It motivated the hierarchical RF that places a small SRAM-based register cache (RC) between functional units and STT-MRAM RF. The RC acts as the write buffer, so all the writes on the RF are first performed on the RC. In the presence of a conflict miss, the RC writes back the corresponding cache line into the RF. - Problem 2) The problem of writting back process
: In this work, we observed that the large amount of such write-back operations are unnecessary because they include register values that are never used again.
▶ CASH-RF(compiler-assisted hierarchical RF in GPUs)
- Solution 2)
: Leveraging this observation, we propose a compiler assisted hierarchical RF in GPUs (CASH-RF) that optimizes STT-MRAM accesses by removing dead register values. In CASH-RF, unnecessary write-back operations are detected by the compiler via the last consumer analysis. At runtime, the corresponding RC lines are discarded after the last references without being updated to the RF.
INTRODUCTION
▶ GPU(Grathics processing units)
: GPUs have been widely used for computing various general-purpose applications. GPUs archieve high throughput by scheduling thousands of threads concurrently.
To exploit such a high degree of thread-level paralleism (TLP), GPUs have three orders of magnitude larger SRAM-based register file (RF) than CPUs. Furthermore, the size of RF tends to increase with each new generation of GPUs.
- Problem 1) The problem of RF(SRAM-based register file)
: Prior works revealed that RF consumes around 20% of the total GPU energy and is one of the most power-hungry components. - Solution 1)
: To reduce RF energy consumption, prior works have proposed GPU architectures that adopts emerging nonvolatile memories, such as STT-MRAM and SOT-MRAM as an RF substrate. - Problem 2) The problem of STT-MRAM
: However, and access to STT-MRAM takes a longer time and consumes more energy. - Solution 2)
: To address this issue, hierarchical RF designs have been proposed that have small-sized SRAM register cache (RC) between functional units and STT-MRAM RF. In such designs register values are first updated to the RC and then weitten back to the RF only when there are no free cache lines in the RC due to conflic misses. - Problem 3) The problem of writting back process.
: This study reveals that a significant portion of the total lines of the RC written back of RF will not be reused in the future. - Solution 3)
: Therefore, STT-MRAM writes can be further reduced if the last consumers of registers are informed by the compiler, and the RC eliminates the corresponding cache lines after their last references. Based on this observation, this letter proposes a compiler-assisted hierarchical RF for GPUs (CASH-RF). For each instruction, the compiler generates a bit vector that indicates whether the current instruction is the last consumer of each source operand register. Then, the RC uses thses bit vectors to invalidate the cache lines of the RC when the corresponding instructions completer reading date, which dramatically reduces the number of unnecessary write-back operations.
MOTIVATION AND CACH-RF ARCHITECTURE
A. Register Read and Write Operations
▶ RC
: The key role of RC is to reduce the access to STT-MRAM RF, thereby minimizing performance loss and improving energy efficiency. Due to the high temporal locality observed in general-purpose applications on GPUs, the RC could absorve a number of repeated accesses to the same register.

In CASH-RF, such a write back operation is removed referring to the last reference information generated by the compiler.
- Similar to the hierarchical RF, i13 first updates RF.
- Then, CASH-RF invalidates the cache line corresponding to R5 after i24 reads the value because R5 is never used again by the following instructions. This information is encoded in the last reference bit (LRB) vector that indicates the location of dead register in an instruction.
B. CASH-RF Degisn
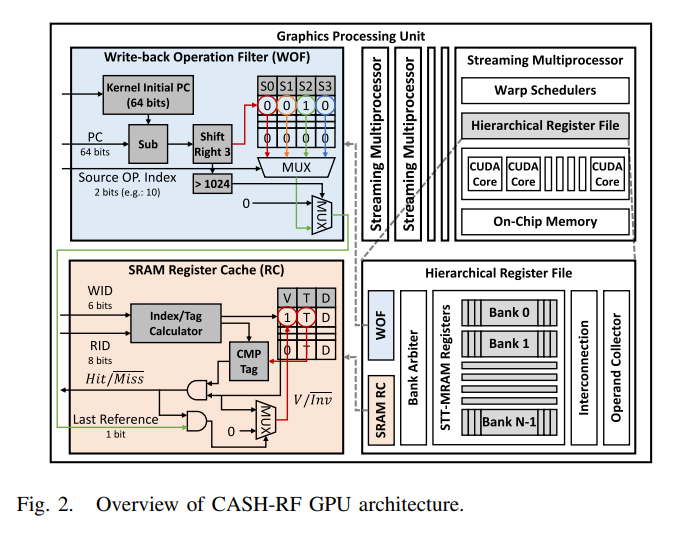
**The blue and red boxes represent the write-back operation filter(WOF) and the proposed SRAM RC, respectively.
▶ WOF(wirte-back operation filter)
: The WOF holds dead register information generated by the compiler and delivers it to the RC when a corresponding register is read by the operand collector
▶ Compiler Support
: To identify whether the incoming read request is the last one for a specific register, we modify the compiler to generated LRB vectors. The compiler checks the instruction in order and determines each LRB by checking whether the instruction uses the corresponding register as the source operand for the last time. The last time can be confirmed if the corresponding source register lastly appear or it is updated by the succeeding instructions.
- Loop
In our modified compiler, instructions in the loop must be carefully handled to generate LRB vectors. In the loop, simply checking the instruction order may generate incorrect LRB vectors since registers can be reused by instructions of the next loop iteration(반복).
To handle such a case, the compiler iterates(반복하다) the instructions tin every loop twice and generages LRB bectors; then, there are always a pair of LRB vectors for the instructions. If LRB is set on a pair of both vectors, then the corresponding register can be invalidated since there are no loop-carred dependencies. However, if LRB is set on only one vector, then the corresponding register is possibly reused by subsequent iterations (loop-carried dependency), thus LRB must be invalidated. Note, that one list of LRB vectors can be shared by all threads since GPUs spaqn many threads originating from the same kernel code.
CONCLUSION
This letter proposes the CASH-RF architecture to minimize the write operations in the hierarchical RF design.
In CASH-RF, the cache lines of the SRAM RC are discarded after the last reading requests, which can be determined by the last consumer analysis. To support the invalidation technique, a new RC design is proposed along with the WOF.
Due to the cache line invalidation, CASH-RF eliminates the 59.5% of unnecessary write operations. Consequently, CASH-RF improves the energy efficiency by 54.7% with only 2.6% performance degradation compared to the baseline GPUs.
https://ieeexplore.ieee.org/document/9745582
CASH-RF: A Compiler-Assisted Hierarchical Register File in GPUs
Spin-transfer torque magnetic random-access memory (STT-MRAM) is an emerging nonvolatile memory technology that has been received significant attention due to its higher density and lower leakage current over SRAM. One compelling use case is to employ STT-
ieeexplore.ieee.org
'논문' 카테고리의 다른 글
| GPU Register File의 Bank Conflict 분석 (0) | 2023.08.24 |
|---|---|
| GCN 아키텍쳐 상에서의 OpenCL을 이용한 GPGPU 성능향상 기법 연구 (0) | 2023.08.22 |
| GPU 컴퓨팅에서 빠른 데이터 전송을 위한 메모리 피닝 자동 관리 (0) | 2023.08.21 |
| 다중 워크로드 환경을 위한 GPGPU 스레드 블록 스케줄링 (0) | 2023.05.05 |
| GPU 메모리 접근 시간 부채널 특성 분석 (0) | 2023.05.01 |


