Control Unit Structure
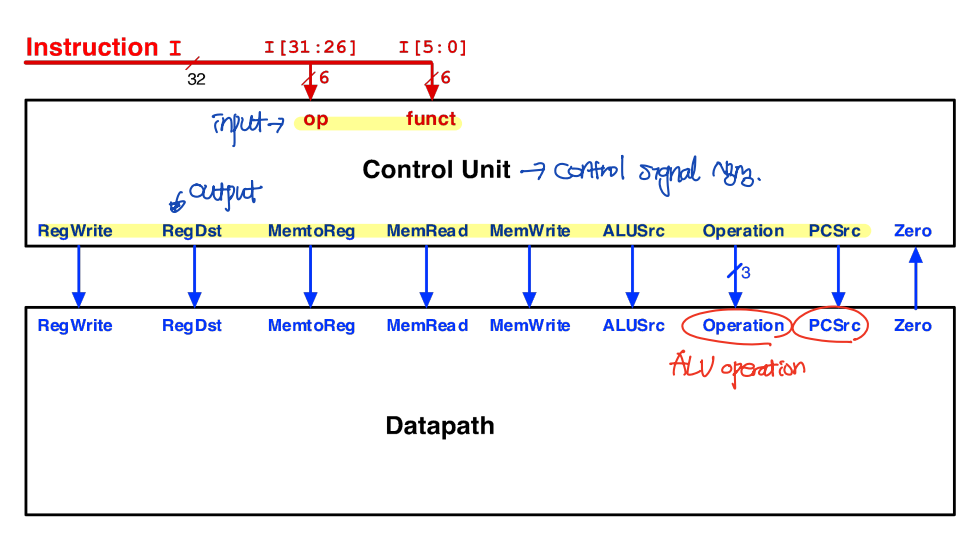
1. Modified Control Unit Structure
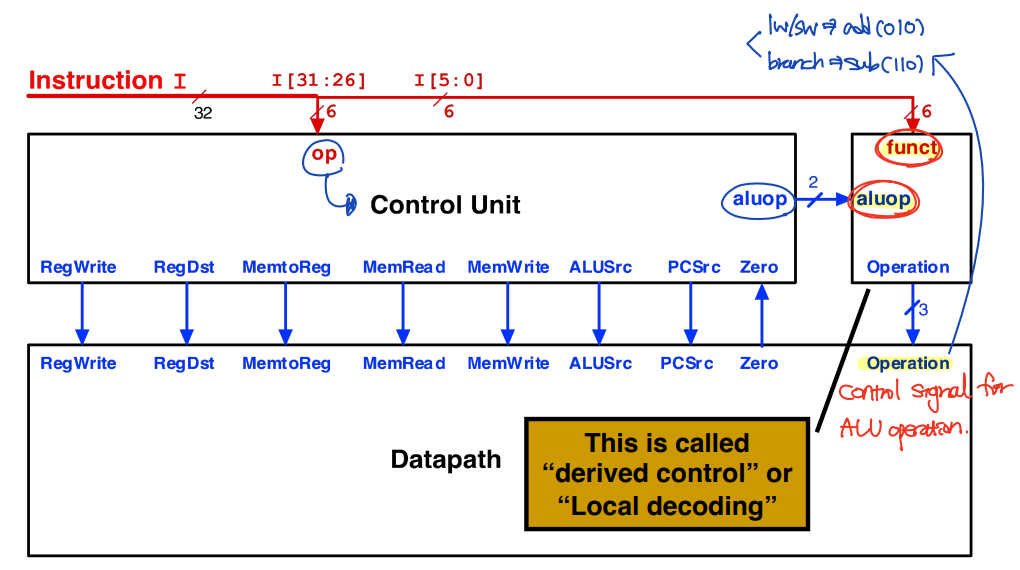
- funct + ALUop --> ALU operation
: 2비트 제어 필드(ALUop), 6비트 funct 필드를 사용하여 ALU operation을 만든다. (decomposing)
(ALU operation부터 생각하자!)
Processor Design - ALU Operation

- Opcode를 이용해서 ALUop를 만든다.
- ALUop, funct를 이용해서 Operation을 만든다.
ALU Usage in Processor Design


▶ Data transfer(lw, sw): ALUop --> ALU operation (항상 addition이다.)
▶ Branch(beq): ALUop --> ALU operation (항상 subtraction이다.)
▶ R-type: ALUop + funct --> ALU operation (funct 필드의 하위 4비트가 중요하다.)
ALU Control - Truth Table

▶ Data transfer(lw, sw): 00 --> Operation (add)
▶ Branch(beq): 01 (11이 없기 때문에, x1로 본다!) --> Operation (sub)
▶ R-type: 1x + F3,F2,F1,F0 --> Operation
ALU Control - Implementation

2. One More Modification - for Branch
- Branch(beq)에서는 (zero == 1)일 때, branch한다.
--> Zero + Branch --> PCSrc
- Zero: ALU subtraction 값이 0이면, Zero = 1;
- Branch: beq(branch on equal)이면, Branch = 1;
Processor Design - PCSrc

3. Final Extenstion: Implementing j (jump)
- jump: (PC+4)의 상위 4비트_address*4 (concatencation; 연접)
Processor Design - CONCAT

Thr Problem with Single-Cycle Processor Implementation: Performance
- Single-Cycle Processor: every 1 instruction in 1 clock cycle
--> Clock cycle time is determinded by the slowest instruction. (Clock cycle time은 가장 느린 instruction보다 길어야 한다.)

Alternatives to Single Cycle
- Multicycle processor: multiple clock cycles per instruction.
- Pipelined implementation
What is Pipelining?
- Piplelining: Overlap execution of multiple instructions.
The Laundry Analogy


Pipelining a Digital System

- Pipelining은 각 명령어의 실행을 끝내는 데 걸리는 시간(지연 시간; latency, execution time)을 단축시키지는 않는다. Pipelining은 명령어의 처리율(throughput)을 향상시킨다.
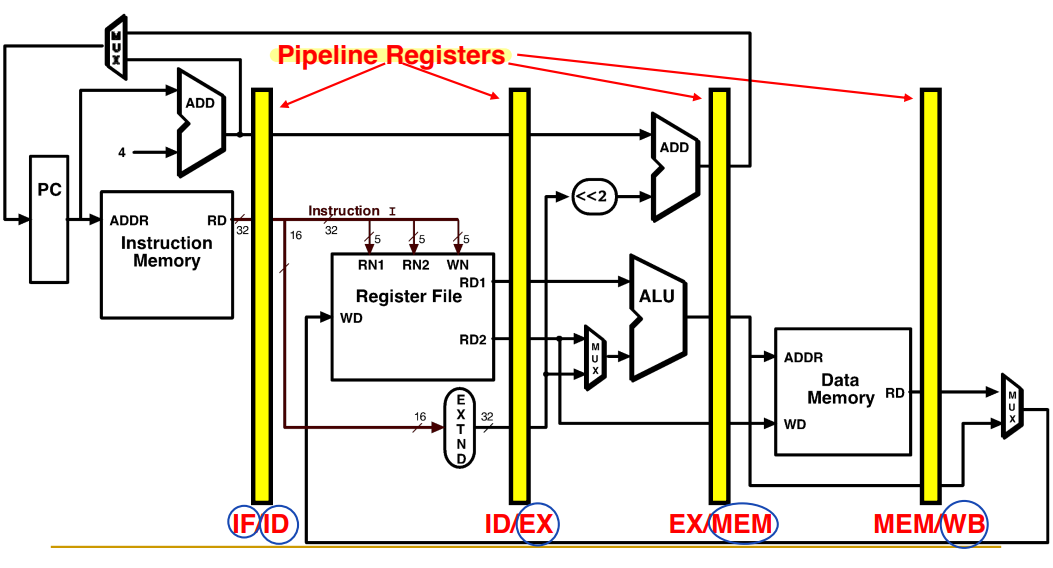
- Pipelining overhead: pipeline register (multiple instruction의 buffer 역할을 한다.)
- Problem: Single-Cycle Processor
- Solution: Pipelining
Pipelining a Processor
- Pipelining: Multiple instructions are being processed at same time.
- IF: Instruction Fetch
- ID: Instruction Decode and Register Read
- ALU: Execution operation or calculate address
- MEM: Memory access
- WB: Write result into register
Single-Cycle Processor

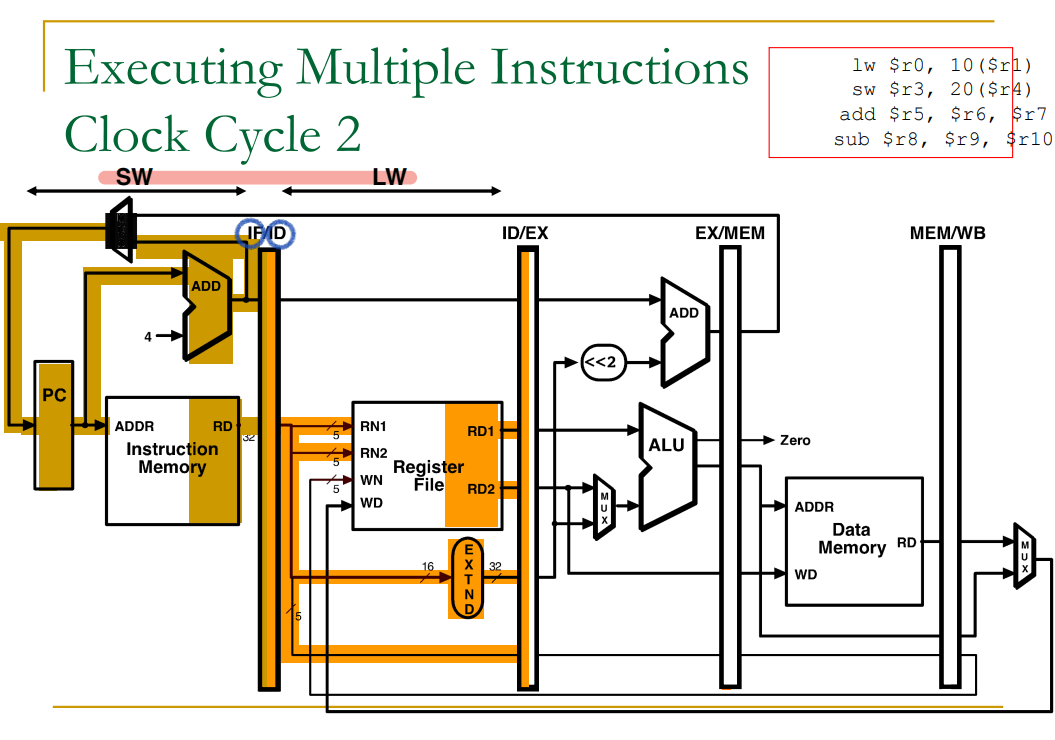
Pipelined Example: Executing Multiple Instructions

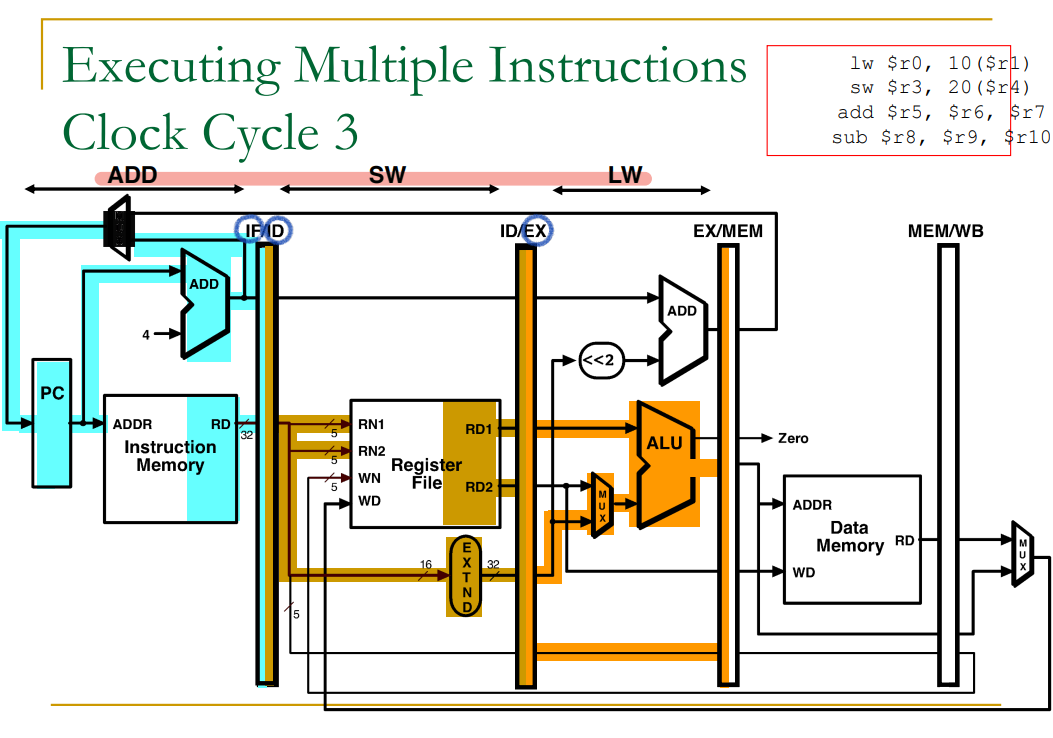
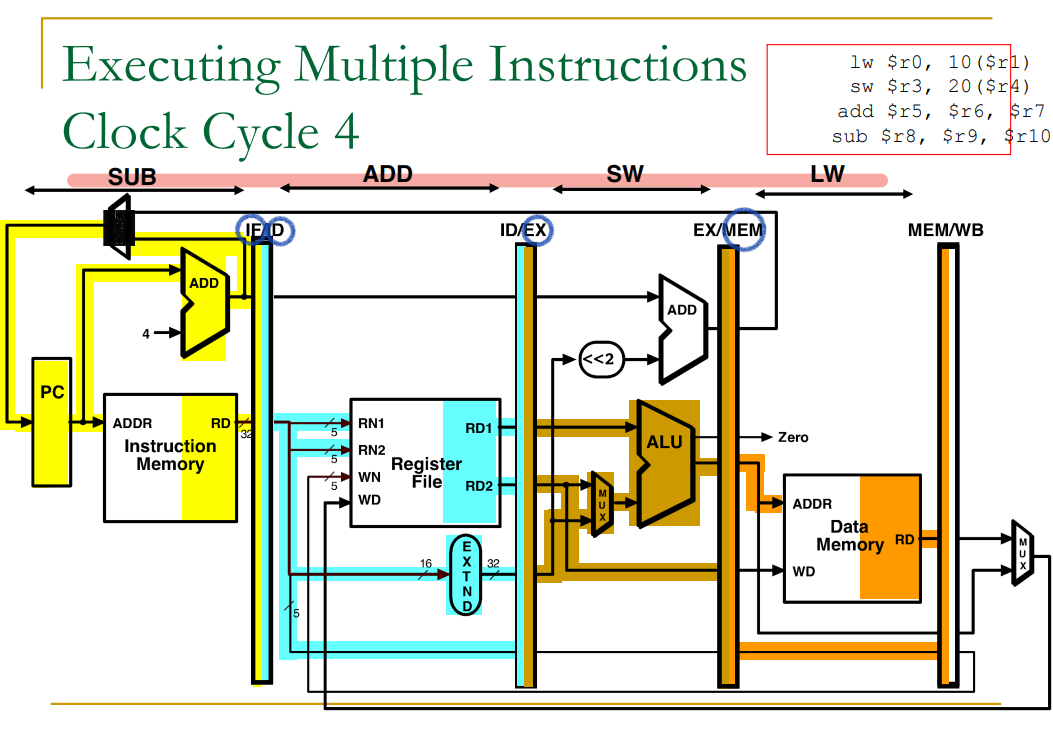


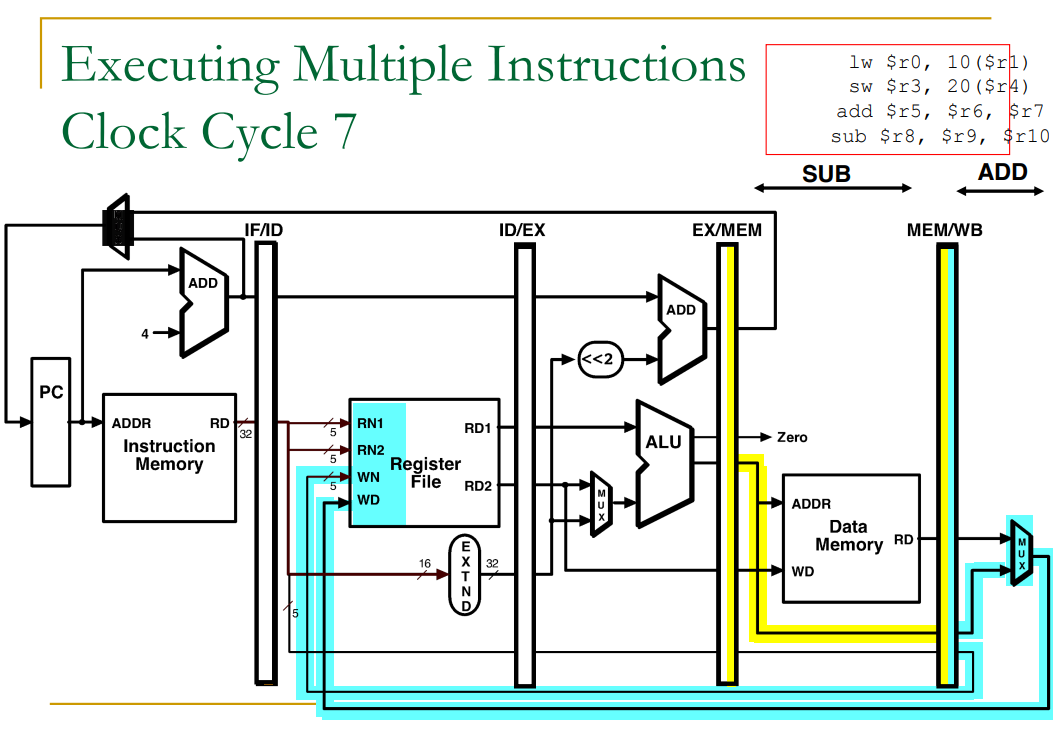

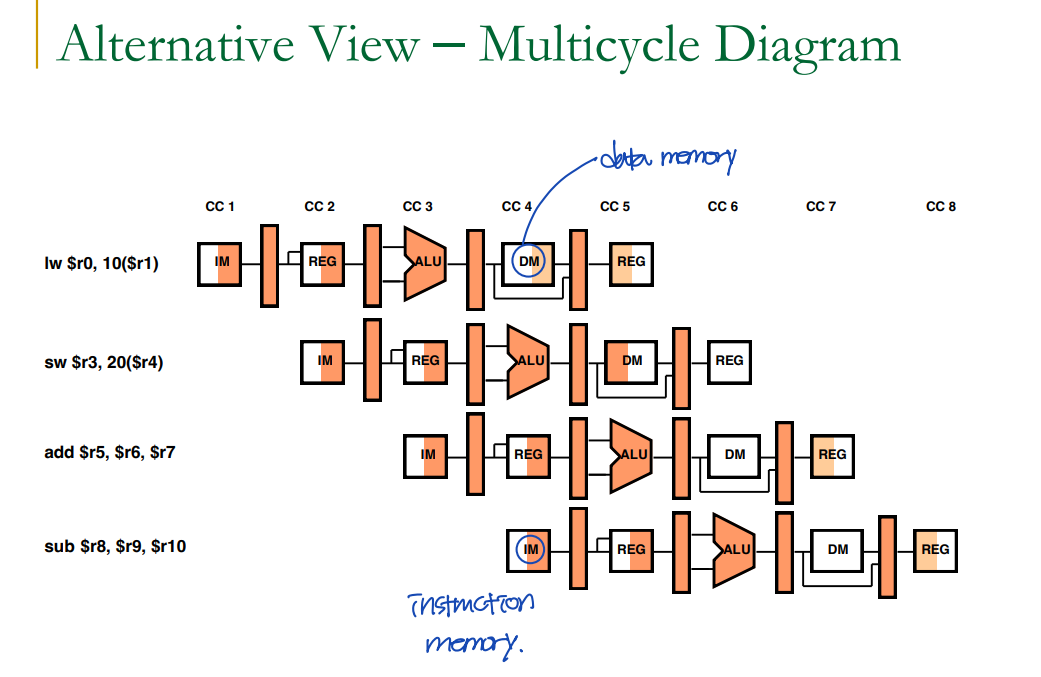
출처: 이화여자대학교 이형준교수님 컴퓨터구조, 컴퓨터 구조 및 설계 (MIPS EDDITION)
'Computer Architecture > 컴퓨터구조[01]' 카테고리의 다른 글
| [컴퓨터구조] 1106 (0) | 2023.11.09 |
|---|---|
| [컴퓨터구조] 1101 (0) | 2023.11.05 |
| [컴퓨터구조] 4. The Processor (1) (0) | 2023.10.22 |
| [컴퓨터구조] 3. Arithmetic for Computers (4) (0) | 2023.10.22 |
| [컴퓨터구조] 3. Arithmetic for Computers (3) (0) | 2023.10.22 |



