15.1 이번 장에서 만들어 볼 프로그램
15.2 표준 템플릿 라이브러리(STL: Standard Templete Library)
: 프로그래머들이 공통적으로 사용하는 자료구조와 알고리즘을 구현한 클래스
- 컨테이너: 자료를 저장하는 창고와 같은 역할을 하는 구조 - 배열, 연결리스트, 벡터, 집합, 사전, 트리 등
- 반복자(iterator): 컨테이너의 요소를 가리키는 데 사용된다.
- 알고리즘
- 탐색(find): 컨테이너 안에서 특정한 자료를 찾는다.
- 정렬(sort): 자료들을 크기순으로 정렬한다.
- 반전(reverse): 자료들의 순서를 역순으로 한다.
- 삭제(remove): 조건이 만족되는 자료를 삭제한다.
- 변환(transform): 컨테이너의 요소들을 사용자가 제공하는 변환 함수에 따라서 변환한다.
15.3 컨테이너
- 벡터(vector): 동적 배열처럼 동작한다. 뒤에서 자료들이 추가된다.
- 큐(queue): 데이터가 입력된 순서대로 출력되는 자료구조
- 스택(stack): 먼저 입력된 데이터가 나중에 출력되는 자료구조
- 우선순위큐(priority queue): 큐의 일종으로, 큐의 요소들이 우선순위를 가지고 있고, 우선순위가 높은 요소가 먼저 출력되는 자료구조
- 리스트(list): 벡터와 유사하지만, 중간에서 자료를 추가하는 연산이 효율적이다.
- 집합(set): 중복이 없는 자료들이 정렬되어서 저장된다.
- Map: 키-값(key-value)의 형식으로 저장된다.
▶ 컨테이너의 분류
- 순차 컨테이너: 자료를 순차적으로 가지고 있다. 순차적인 컨테이너에서는 자료의 추가는 빠르지만, 탐색할 때는 시간이 많이 걸린다. (벡터, 리스트 등)
- 연관 컨테이너: 사전과 같은 구조를 사용해서 자료를 저장한다. 연관 컨테이너는 원소들을 검색하기 위한 키(key)를 가지고 있다. 자료들은 정렬되어 있다. 자료의 추가에는 시간이 걸리지만, 자료의 탐색은 매우 빠르다. (Map, 집합 등)
/* list container */
#include <iostream>
#include <time.h>
#include <list>
using namespace std;
int main() {
list<int> values; // list
srand(time(NULL));
for (int i = 0; i < 10; i++) {
values.push_back(rand() % 100); // push_back
}
values.sort(); // sort
for (auto& e : values) {
cout << e << " ";
}
return 0;
}15.4 반복자(iterator)
: 컨테이너의 요소를 가리키는 객체 (일반화된 포인터: generalized pointer)
vector<int> vec; // 벡터 선언
vector<int>::iterator it; // 반복자 선언: it
for(it = vec.begin(); it != c.end(); it++)
cout << *it << " "; // 반복자를 이용해서 요소의 값을 추출한다.
▶ 반복자의 종류
- 전향 반복자(forward iterator): ++연산자만 가능하다.
- 양방향 반복자(bidirectional iterator): ++연산자와 --연산자가 가능하다.
- 무작위 접근 반복자(random access iterator): ++연산자와 --연산자, [ ] 연산자가 가능하다.
▶ auto

#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto p = v.begin(); p != v.end(); ++p)
cout << *p << endl; // *p
return 0;
}
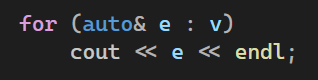
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto& e : v)
cout << e << endl;
return 0;
}15.5 컨테이너의 공통 멤버 함수
Container() // 기본 생성자
Container(size) // 크기가 size인 컨테이너 생성
Container(size, value) // 크기가 size이고, 초기값이 value인 컨테이너 생성
Container(iterator, iterator) // 다른 컨테이너로부터 초기값의 범위를 받아서 생성size() // 컨테이너의 크기
begin() // 첫 번째 요소의 반복자 위치
end() // 반복자가 마지막 요소를 지난 위치
clear() // 모든 요소를 삭제
empty() // 비어있는지 검사
erase(iterator) // 컨테이너의 중간 요소를 삭제
erase(iterator, iterator) // 컨테이너의 지정된 범위를 삭제
front() // 컨테이너의 첫 번째 요소 반환
insert(iterator, value) // 컨테이너 중간에 value를 삽입
push_back(value) // 컨테이너의 끝에 데이터 추가
pop_back() // 컨테이너의 마지막 요소를 삭제
rbegin() // 끝을 나타내는 역반복자
rend() // 역반복자가 처음을 지난 위치
operator=(Container) // 대입 연산자의 중복 정의15.6 벡터
vector<int> v;15.7 덱(deque: double-ended queue)
: 양방향으로 커질 수 있도록 구현한 동적 배열
Deque과 Vector가 다른 점은, deque의 경우, 전단과 후단에서 모두 요소를 추가하고 삭제하는 것을 허용한다는 점이다.
Deque의 끝과 시작 부분에 요소를 추가하는 것이 빠르다. 중간에 요소를 추가하려면 요소를 이동해야 하므로 시간이 걸린다.
#include <deque>
deque<int> dq;
/* Deque Example */
#include <iostream>
#include <deque>
using namespace std;
int main() {
deque<int> dq = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
dq.pop_front(); // 앞에서 삭제
dq.push_back(11); // 끝에서 추가
for (auto& e : dq)
cout << e << " ";
return 0;
}15.8 리스트(list)
리스트(list)는 외부에서 보면 벡터와 완전히 동일하다. 벡터와 마찬가지로 순차적인 데이터를 저장한다. 벡터를 리스트로 대체하는 것도 가능하다.
하지만 벡터와 리스트는 내부 구조가 다르다. 리스트 컨테이너는 이중 연결 리스트로 구현한다. 이중 연결 리스트는 중간 위치에서 삽입이나 삭제가 빈번한 경우에 효율적인 자료구조이다. 이중 연결 리스트에서는 모든 노드가 앞 노드와 뒤 노드를 가리키는 포인터를 동시에 가지고 있다. 따라서 반복자를 이용해서 양방향으로 이동하는 것이 가능하다.
만약 삽입이나 삭제가 양 끝단에서만 빈번하게 발생한다면, 덱(deque)을 사용하는 것이 유리하다.
list 클래스는 순차 컨테이너 클래스들이 가지고 있는 공통 멤버 함수에 추가로
push_front()
pop_front()
remove()
unique()
merge()
reverse()
sort()
splice()등을 가지고 있다.
▶ 벡터와 리스트의 차이점:
- 벡터는 임의 접근이 가능하지만, 리스트에서는 불가능하다. 리스트는 [ ] 연산자를 지원하지 않으며, 리스트에서 어떤 요소에 접근하려면 첫 번째 요소부터 순차적으로 이동해야 한다. 따라서 임의 접근 반복자를 필요로하는 binary_search()와 같은 알고리즘은 적용할 수 없다.
- 벡터에서는 중간 위치에 삽입이나 삭제를 하려면, 뒤의 요소들을 이동하여야 하므로 시간이 오래 걸린다. 반면에 리스트에서는 앞 노드의 링크만 조작하면 되므로 매우 효율적으로 삽입이나 삭제를 할 수 있다.
- 리스트에서는 각 데이터마다 링크를 저장해야 하므로 기억공간을 더 많이 차지한다. 반면에 벡터는 데이터만이 저장되므로, 크기가 더 작다.
#include <list>
list<int> myList;
/* list로 중간에 자료 추가하기 */
#include <iostream>
#include <list>
using namespace std;
int main() {
list<int> myList = { 10, 20, 30, 40 };
auto it = myList.begin();
it++;
it++;
myList.insert(it, 25);
for (auto& e : myList)
cout << e << " "; // 10 20 25 30 40
return 0;
}
/* iterator로 위치 정해서 list에 insert하기 */
#include <iostream>
#include <list>
#include <algorithm>
#include <string>
using namespace std;
int main() {
list<string> myList = { "file", "edit", "view", "help" };
auto it = find(myList.begin(), myList.end(), "view");
myList.insert(it, "tools");
for (auto& e : myList)
cout << e << " "; // file edit tools view help
return 0;
}15.9 집합
: 순서에 상관없이 자료만 저장하고 싶은 경우에 사용하는 자료구조이다. 집합에 저장된 자료를 키(key)라고 한다. 집합(set)은 동일한 키를 중복해서 가질 수 없다.
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> mySet;
mySet.insert(1); // insert
mySet.insert(2);
mySet.insert(3);
auto pos = mySet.find(2); // find
if (pos != mySet.end())
cout << "발견되었음";
else
cout << "발견되지 않았음";
return 0;
}15.10 Map
: 많은 데이터 중에서 원하는 데이터를 빠르게 찾을 수 있는 자료구조이다. Map은 사전과 같은 자료구조이다. 사전처럼 단어(key)가 있고, 이것에 대한 설명(value)가 있다. Map은 중복된 키를 가질 수 없다. 각 키는 오직 하나의 값에만 매핑될 수 있다. 키가 제시되면 Map은 값을 반환한다.
Map의 객체를 생성하기 위해서는 두 가지의 타입을 명시해야 한다. 하나는 키(key)를 위한 타입이고, 또 하나는 값(value)을 위한 타입이다.
map<string, string> myMap;
▶ Map에 데이터를 저장하는 방법: [ ] 연산자 이용
myMap["이지원"] = 010-0000-0000;
▶ Map에서 어떤 자료를 찾을 때: [ ] 연산자 이용
string ans = myMap["이지원"];
/* 학생들의 이름을 key로 하여서 전화번호를 저장하는 프로그램 */
#include <iostream>
#include <map>
using namespace std;
int main() {
map<string, string> myMap;
myMap["김철수"] = "000";
myMap["이지원"] = "111";
myMap["나나나"] = "222";
for (auto& e : myMap)
cout << e.first << "::" << e.second << endl;
if (myMap.find("김영희") == myMap.end())
cout << endl << "발견되지 않음";
else
cout << "발견됨";
return 0;
}15.11 컨테이너 어댑터(container adapter)
: 이미 존재하는 컨테이너를 변경하여 새로운 기능을 제공하는 클래스
즉, 기존의 컨테이너의 기능을 그대로 이용하면서 새로운 기능이나 인터페이스를 제공하는 것
- 스택, 큐, 우선순위큐
스택(stack)
- Last-in First-out 자료구조
: 스택을 구현하기 위해서는 선형적인 자료구조만 있으면 된다. 스택은 벡터, 리스트, 덱 등을 사용해서 구현할 수 있다. 디폴트는 덱을 이용한다.
void push(const value_type& v) // 스택에 v를 삽입한다.
void pop() // 스택의 상단 원소를 삭제한다.
value_type& top() const // 스택의 상단 원소를 반환한다.
bool empty() const // 스택이 공백이면 true를 복귀한다.
size_type size() const // 스택에 있는 원소의 개수를 반환한다.#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<string> st;
string sayings[3] = { "aa", "bb", "cc" };
for (auto& e : sayings)
st.push(e); // st.push()
while (!st.empty()) {
cout << st.top() << endl; // st.top()
st.pop(); // st.pop()
}
return 0;
}
큐(queue)
- First-in First-out
: 주로 큐는 데이터를 처리하기 전에 잠시 저장하고 있는 용도로 사용된다.
큐는 후단(tail)에서 데이터를 추가하고, 전단(head)에서 데이터를 삭제한다. 큐에서도 스택과 마찬가지로 중간에서 데이터를 추가하거나 삭제할 수 없다.
void push(const value_type& v) // 큐의 끝에 v를 삽입한다.
void pop() // 큐의 첫 번째 원소를 삭제한다.
value_type& front() const // 큐의 첫 번째 원소를 반환한다.
value_type& back() const // 큐의 마지막 원소를 반환한다.
bool empty() const // 큐가 공백이면 true를 반환한다.
size_type size() const // 큐의 원소 개수를 반환한다.#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> myQueue;
myQueue.push(100);
myQueue.push(200);
myQueue.push(300);
while (!myQueue.empty()) {
cout << myQueue.front() << endl; // Queue: front, Stack: top
myQueue.pop(); // pop()
}
return 0;
}
우선순위큐(priority_queue)
: 우선순위큐는 큐와 비슷하지만, 원소들이 우선순위를 가지고 있다. 원소들은 들어온 순서와 상관없이 우선순위가 높은 원소가 먼저 나가게 된다.
우선순위큐는 히프(heap)라고 하는 자료구조를 내부적으로 사용한다.
우선순위큐의 가장 대표적인 예는 작업 스케줄링(job scheduling)이다.
#include <queue>
priority_queue<int> pq;
15.12 STL 알고리즘의 소개
#include <algorithm>
▶ 불변경 알고리즘:
// 개수 알고리즘
count() // 주어진 값과 일치하는 요소들의 개수를 센다.
count_if() // 주어진 조건에 맞는 요소들의 개수를 센다.
// 탐색 알고리즘
search() // 주어진 값과 일치하는 첫번째 요소를 반환한다.
search_n() // 주어진 값과 일치하는 n개의 요소를 반환한다.
find() // 주어진 값과 일치하는 첫번째 요소를 반환한다.
find_if() // 주어진 조건에 일치하는 첫번째 요소를 반환한다.
find_end() // 주어진 조건에 일치하는 마지막 요소를 반환한다.
binary_search() // 정렬된 컨테이너에 대하여 이진탐색을 수행한다.
// 비교 알고리즘
equal() // 두개의 요소가 같은지 비교한다.
mismatch() // 두개의 컨테이너를 비교해서, 일치하지 않는 첫번째 요소를 반환한다.
lexicographical_compare() // 두개의 순차 컨테이너를 비교해서, 사전적으로 어떤 컨테이너가 작은지를 반환한다.
▶ 변경 알고리즘:
// 초기화 알고리즘
fill() // 지정된 범위의 모든 요소를 지정된 값으로 채운다.
generate() // 지정된 함수의 반환값을 할당한다.
// 변경 알고리즘
for_each() // 지정된 범위의 모든 요소에 대하여 연산을 수행한다.
transform() // 지정된 범위의 모든 요소에 대하여 함수를 적용한다.
// 복사 알고리즘
copy() // 하나의 구간을 다른 구간으로 복사한다.
// 삭제 알고리즘
remove() // 지정된 구간에서 지정된 값을 가지는 요소들을 삭제한다.
unique() // 구간에서 중복된 요소들을 삭제한다.
// 대치 알고리즘
replace() // 지정된 구간에서 요소가 지정된 값과 일치하면 대치값으로 바꾼다.
// 정렬 알고리즘
sort() // 지정된 정렬 기준에 따라서 구간의 요소들을 정렬한다.
// 분할 알고리즘
partition() // 지정된 구간의 요소들을 조건에 따라서 두개의 집합으로 나눈다.15.13 많이 사용되는 알고리즘
find(), find_if()
: 컨테이너에서 무엇을 찾으려면 find() 알고리즘을 사용할 수 있다.
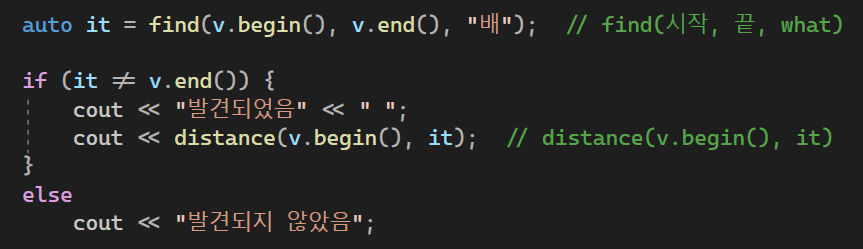
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
int main() {
vector<string> v = { "사과", "토마토", "배", "수박", "키위" };
auto it = find(v.begin(), v.end(), "배"); // find(시작, 끝, what)
if (it != v.end()) {
cout << "발견되었음" << " ";
cout << distance(v.begin(), it); // distance(v.begin(), it)
}
else
cout << "발견되지 않았음";
return 0;
}#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
// 문자열 s가 '김'을 포함하면 true 반환
bool checkKim(string s) {
if (s.find("김") != string::npos) return true;
else return false;
}
int main() {
vector<string> v = { "김철수", "박문수", "강감찬", "김유신", "이순신" };
auto it = v.begin();
while (1) {
it = find_if(it, v.end(), checkKim); // find_if(시작, 끝, 조건)
if (it == v.end()) break; // 탐색 실패
cout << "위치" << distance(v.begin(), it) << "에서 " << *it << "를 탐색하였음" << endl;
it++;
}
return 0;
}
count()
: 주어진 값과 일치하는 요소의 개수를 세는 함수
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
template <typename T> // template
bool isEven(int n) {
return (n % 2 == 0);
}
int main() {
vector<int> v;
for (int i = 0; i < 10; i++) {
v.push_back(i);
}
int ans = count_if(v.begin(), v.end(), isEven<int>); // isEven<int> 조건
cout << ans;
return 0;
}
binary_search()
탐색이란 리스트 안에서 원하는 원소를 찾는 것이다. 만약 리스트가 정렬되어 있지 않다면, 처음부터 모든 원소를 방문할 수밖에 없다. (선형탐색)
하지만 리스트가 정렬되어 있다면, 중간에 있는 원소와 먼저 비교하는 것이 좋다. (이진탐색) 정렬된 리스트에서 만약 찾고자 하는 원소가 중간 원소보다 크면 찾고자 하는 원소는 뒷부분에 있고, 반대이면 앞부분에 있다. 이런 식으로 하여서 문제의 크기를 반으로 줄일 수 있다.
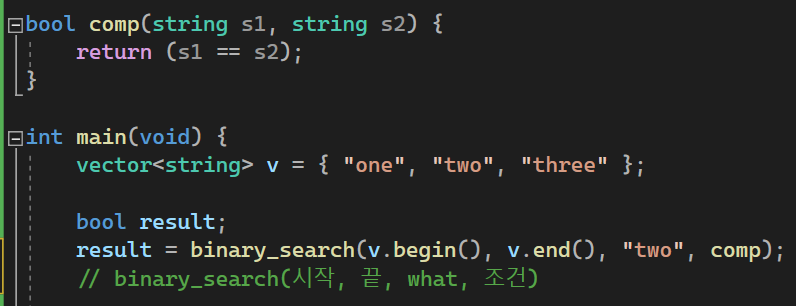
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
using namespace std;
bool comp(string s1, string s2) {
return (s1 == s2);
}
int main(void) {
vector<string> v = { "one", "two", "three" };
bool result;
result = binary_search(v.begin(), v.end(), "two", comp); // binary_search(시작, 끝, what, 조건)
if (result == true)
cout << "발견되었음";
else
cout << "발견되지 않음";
return 0;
}
copy(), reverse()
- copy(): 컨테어너의 원소들을 복사한다.
- reverse(): 컨테이너의 모든 요소들을 역순으로 배치한다.

#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v1 = { 1, 2, 3, 4 };
vector<int> v2(4);
copy(v1.begin(), v1.end(), v2.begin());
for (auto& e : v2)
cout << e << " ";
return 0;
}
for_each()
: 컨테이너의 요소에 대해 funct()를 호출한다. 함수 funct()의 요소를 변경할 수도 있다.
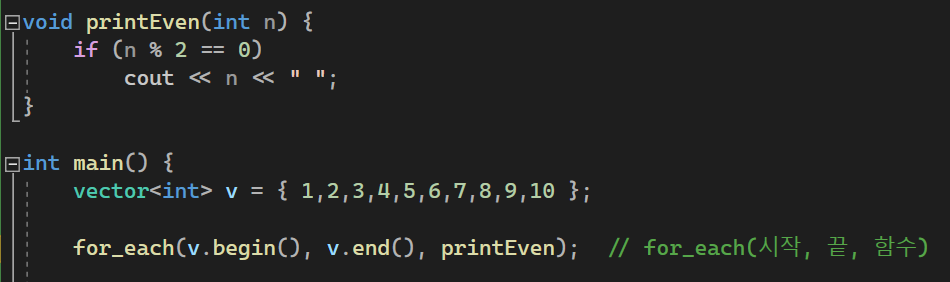
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void printEven(int n) {
if (n % 2 == 0)
cout << n << " ";
}
int main() {
vector<int> v = { 1,2,3,4,5,6,7,8,9,10 };
for_each(v.begin(), v.end(), printEven); // for_each(시작, 끝, 함수)
return 0;
}
sort()
: 합병 정렬
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool function(int i, int j) {
return i < j;
}
int main() {
vector<int> list = { 9, 12, 33, 78, 15, 3, 80, 26 };
sort(list.begin(), list.end()); // sort(시작, 끝)
for (auto& e : list)
cout << e << " ";
cout << endl;
random_shuffle(list.begin(), list.end()); // 컨테이너의 요소를 다시 섞는 함수
sort(list.begin(), list.end(), function); // sort(시작, 끝, how)
for (auto& e : list)
cout << e << " ";
return 0;
}15.14 람다식
'Programming > C++' 카테고리의 다른 글
| [어서와 C++는 처음이지!] CH8 Exercise (1) | 2024.02.12 |
|---|---|
| [C++] 8. 포인터와 동적객체 생성 (1) | 2024.02.12 |
| [어서와 C++는 처음이지!] CH6 Exercise (1) | 2024.01.30 |
| [C++] 6. 객체 배열과 벡터 (1) | 2024.01.30 |
| [어서와 C++는 처음이지!] CH5 Exercise (0) | 2024.01.29 |
