MMPose 1.0은 새로운 프레임워크를 기반으로 구축되었다. 딥러닝에 대한 기본 지식을 가진 개발자를 위해 이 튜토리얼은 MMPose 1.0 프레임워크 디자인에 대한 개요를 제공한다. 이전 버전의 MMPose를 사용한 경험이 있거나, MMPose 1.0을 처음 시작하는 초보자라면 이 튜토리얼을 통해 MMPose 1.0을 기반으로 프로젝트를 구축하는 방법을 배울 수 있다.
참고 사항
이 튜토리얼은 MMPose 1.0을 사용할 때 개발자가 고려해야 할 사항들을 다룬다:
- 전체 코드 아키텍처
- 구성 파일로 모듈 관리하는 방법
- 사용자 정의 데이터셋 사용하는 방법
- 새로운 모듈(백본, 헤드, 손실 함수 등) 추가하는 방법
튜토리얼의 구성
이 튜토리얼의 내용은 다음과 같이 구성된다:
- MMPose 프레임워크에 대한 20분 가이드
- 구조 (Structure)
- 개요
- Step 1: 구성 파일 (Configs)
- Step 2: 데이터 (Data)
- 데이터셋 메타 정보 (Dataset Meta Information)
- 데이터셋 (Dataset)
- 파이프라인 (Pipeline)
- i. 증강 (Augmentation)
- ii. 변환 (Transformation)
- iii. 인코딩 (Encoding)
- iv. 포장 (Packing)
- Step 3: 모델 (Model)
- 데이터 전처리기 (Data Preprocessor)
- 백본 (Backbone)
- 넥 (Neck)
- 헤드 (Head)
Structure
mmpose
|----apis
|----structures
|----configs
|----datasets
|----codecs
|----models
|----engine
|----testing
|----evaluation
|----utils
|----visualizationmmpose
|----apis
|----inferencers
|----structures
|----bbox
|----keypoint
|----configs
|----_base_
|----body_2d_keypoint
|----wholebody_2d_keypoint
|----datasets
|----datasets
|----transforms
|----codecs
|----utils
|----models
|----backbones
|----datapreprocessors
|----distillers
|----heads
|----losses
|----necks
|----pose_estimators
|----task_modules
|----utils
|----engine
|----hooks
|----optim_wrappers
|----schedulers
|----testing
|----utils
|----visualization
|----evaluation
|----evaluators
|----functional
|----matrics
|----utils
|----visualization- apis: 모델 추론을 위한 고수준 API를 제공한다.
- structures: bbox, keypoint 및 PoseDataSample과 같은 데이터 구조를 제공한다.
- datasets: 포즈 추정을 위한 다양한 데이터셋을 지원한다.
- transforms: 유용한 데이터 증강 변환을 많이 포함하고 있다.
- codecs: 포즈 인코더와 디코더를 제공한다. 인코더는 포즈(주로 키포인트)를 학습 목표(예: 히트맵)로 인코딩하고, 디코더는 모델 출력을 포즈 예측으로 디코딩한다.
- models: 모듈형 구조로 포즈 추정 모델의 모든 구성 요소를 제공한다.
- pose_estimators: 모든 포즈 추정 모델 클래스를 정의한다.
- data_preprocessors: 모델의 입력 데이터를 전처리한다.
- backbones: 백본 네트워크 모음을 제공한다.
- necks: 다양한 넥 모듈을 포함한다.
- heads: 포즈 추정을 수행하는 다양한 예측 헤드를 포함한다.
- losses: 다양한 손실 함수를 포함한다.
- engine: 포즈 추정과 관련된 런타임 구성 요소를 제공한다.
- hooks: 러너의 다양한 훅을 제공한다.
- evaluation: 모델 성능 평가를 위한 지표를 제공한다.
- visualization: 스켈레톤, 히트맵 및 기타 정보를 시각화한다.
Overview
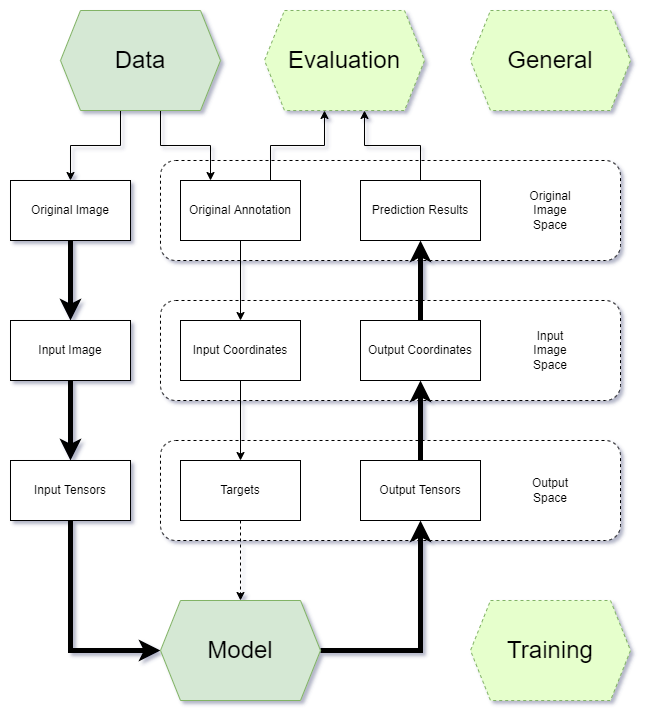
개발자가 프로젝트 개발 중에 사용할 다섯 가지 주요 부분이 있다:
- General: Environment, Hook, Checkpoint, Logger, etc.
- Data: Dataset, Dataloader, Data Augmentation, etc.
- Training: Optimizer, Learning Rate Scheduler, etc.
- Model: Backbone, Neck, Head, Loss function, etc.
- Evaluation: Metric, Evaluator, etc.
이 중 일반, 훈련 및 평가와 관련된 모듈은 주로 MMEngine이라는 훈련 프레임워크에서 제공하며,
개발자는 API 호출 및 매개변수 조정만 하면 된다. 개발자는 주로 데이터와 모델 부분을 구현하는 데 집중한다.
Step1: Configs
MMPose에서는 프로젝트 전체의 정의와 매개변수 관리를 위해 Python 파일을 구성 파일로 사용한다. 따라서 처음 MMPose를 사용하는 개발자는 Configs를 참조하는 것을 강력히 권장한다.
모든 새로운 모듈은 구성 파일에서 인스턴스를 생성하기 전에 Registry를 사용해 등록하고, 해당 디렉토리의 init.py에 임포트해야 한다.
Step2: Data
MMPose에서 데이터의 구성은 다음과 같다:
- 데이터셋 메타 정보(Dataset Meta Infromation)
- 데이터셋(Dataset)
- 파이프라인(Pipeline)
데이터셋 메타 정보(Dataset Meta Information)
포즈 데이터셋의 메타 정보에는 일반적으로 키포인트와 스켈레톤 정의, 대칭 특성 및 키포인트 속성(예: 상체 또는 하체에 속하는지, 가중치 및 시그마)이 포함된다. 이 정보는 데이터 전처리, 모델 훈련 및 평가에서 중요하다. MMPose에서는 데이터셋 메타 정보를 구성 파일 $MMPOSE/configs/base/datasets에 저장한다.
사용자 정의 데이터셋을 MMPose에서 사용하려면 새로운 데이터셋 메타 정보 구성 파일을 추가해야 한다. MPII 데이터셋($MMPOSE/configs/base/datasets/mpii.py)을 예로 들어 보겠다. 다음은 해당 데이터셋의 정보이다:
dataset_info = dict(
dataset_name='mpii',
paper_info=dict(
author='Mykhaylo Andriluka and Leonid Pishchulin and '
'Peter Gehler and Schiele, Bernt',
title='2D Human Pose Estimation: New Benchmark and '
'State of the Art Analysis',
container='IEEE Conference on Computer Vision and '
'Pattern Recognition (CVPR)',
year='2014',
homepage='http://human-pose.mpi-inf.mpg.de/',
),
keypoint_info={
0:
dict(
name='right_ankle',
id=0,
color=[255, 128, 0],
type='lower',
swap='left_ankle'),
## 생략
},
skeleton_info={
0:
dict(link=('right_ankle', 'right_knee'), id=0, color=[255, 128, 0]),
## 생략
},
joint_weights=[
1.5, 1.2, 1., 1., 1.2, 1.5, 1., 1., 1., 1., 1.5, 1.2, 1., 1., 1.2, 1.5
],
# COCO 데이터셋에서 변형
sigmas=[
0.089, 0.083, 0.107, 0.107, 0.083, 0.089, 0.026, 0.026, 0.026, 0.026,
0.062, 0.072, 0.179, 0.179, 0.072, 0.062
])- keypoint_info에는 각 키포인트에 대한 정보가 포함된다.
- name: 키포인트 이름. 키포인트 이름은 고유해야 한다.
- id: 키포인트 ID.
- color: 시각화를 위한 색상([B, G, R]).
- type: 'upper' 또는 'lower', 데이터 증강(RandomHalfBody)에서 사용된다.
- swap: 'swap pair' (즉, 'flip pair')을 나타낸다. 이미지 수평 플립을 적용할 때, 왼쪽 부분은 오른쪽 부분이 되며, 데이터 증강(RandomFlip)에서 사용된다. 키포인트를 이에 맞게 플립해야 한다.
- skeleton_info에는 시각화를 위한 키포인트 연결 정보가 포함된다.
- joint_weights는 각 키포인트에 다른 손실 가중치를 할당한다.
- sigmas는 OKS 점수를 계산하는 데 사용된다. 자세한 내용은 keypoints-eval을 참조하면 된다.
모델 구성 파일에서는 사용자 정의 데이터셋의 메타 정보 경로(예: $MMPOSE/configs/base/datasets/{your_dataset}.py)를 지정해야 한다:
데이터셋(Dataset)
MMPose에서 사용자 정의 데이터셋을 사용하려면 주석을 지원되는 형식(예: COCO 또는 MPII)으로 변환하고 해당 데이터셋 구현을 직접 사용하는 것이 좋다. 이것이 불가능한 경우, 사용자 정의 데이터셋 클래스를 구현해야 할 수도 있다.
사용자 정의 데이터셋 사용에 대한 자세한 내용은 Customize Datasets에서 확인할 수 있다.
▶ 2D Dataset
MMPose의 대부분의 2D 키포인트 데이터셋은 COCO와 유사한 스타일로 주석을 구성한다. 따라서 이러한 데이터셋을 위한 기본 클래스 BaseCocoStyleDataset을 제공한다. 사용자는 BaseCocoStyleDataset을 서브클래싱하고 필요에 따라 메서드(주로 __init__() 및 _load_annotations())를 재정의하여 새로운 사용자 정의 2D 키포인트 데이터셋으로 확장하는 것이 좋다.
MMPose에서 bbox 형식은 xywh 대신 xyxy를 사용하며, 이는 MMDetection과 같은 다른 OpenMMLab 프로젝트에서 사용되는 형식과 일치한다. bbox 형식 변환을 위한 유용한 유틸리티(bbox_xyxy2xywh, bbox_xywh2xyxy, bbox_xyxy2cs 등)를 제공하며, 이는 $MMPOSE/mmpose/structures/bbox/transforms.py에 정의되어 있다.
COCO 형식의 CrowPose 데이터셋($MMPOSE/mmpose/datasets/datasets/body/crowdpose_dataset.py)의 구현을 예로 들어 보겠다.
@DATASETS.register_module()
class CrowdPoseDataset(BaseCocoStyleDataset):
"""CrowdPose dataset for pose estimation.
"CrowdPose: Efficient Crowded Scenes Pose Estimation and
A New Benchmark", CVPR'2019.
More details can be found in the `paper
<https://arxiv.org/abs/1812.00324>`__.
CrowdPose keypoints::
0: 'left_shoulder',
1: 'right_shoulder',
2: 'left_elbow',
3: 'right_elbow',
4: 'left_wrist',
5: 'right_wrist',
6: 'left_hip',
7: 'right_hip',
8: 'left_knee',
9: 'right_knee',
10: 'left_ankle',
11: 'right_ankle',
12: 'top_head',
13: 'neck'
Args:
ann_file (str): Annotation file path. Default: ''.
bbox_file (str, optional): Detection result file path. If
``bbox_file`` is set, detected bboxes loaded from this file will
be used instead of ground-truth bboxes. This setting is only for
evaluation, i.e., ignored when ``test_mode`` is ``False``.
Default: ``None``.
data_mode (str): Specifies the mode of data samples: ``'topdown'`` or
``'bottomup'``. In ``'topdown'`` mode, each data sample contains
one instance; while in ``'bottomup'`` mode, each data sample
contains all instances in a image. Default: ``'topdown'``
metainfo (dict, optional): Meta information for dataset, such as class
information. Default: ``None``.
data_root (str, optional): The root directory for ``data_prefix`` and
``ann_file``. Default: ``None``.
data_prefix (dict, optional): Prefix for training data. Default:
``dict(img=None, ann=None)``.
filter_cfg (dict, optional): Config for filter data. Default: `None`.
indices (int or Sequence[int], optional): Support using first few
data in annotation file to facilitate training/testing on a smaller
dataset. Default: ``None`` which means using all ``data_infos``.
serialize_data (bool, optional): Whether to hold memory using
serialized objects, when enabled, data loader workers can use
shared RAM from master process instead of making a copy.
Default: ``True``.
pipeline (list, optional): Processing pipeline. Default: [].
test_mode (bool, optional): ``test_mode=True`` means in test phase.
Default: ``False``.
lazy_init (bool, optional): Whether to load annotation during
instantiation. In some cases, such as visualization, only the meta
information of the dataset is needed, which is not necessary to
load annotation file. ``Basedataset`` can skip load annotations to
save time by set ``lazy_init=False``. Default: ``False``.
max_refetch (int, optional): If ``Basedataset.prepare_data`` get a
None img. The maximum extra number of cycles to get a valid
image. Default: 1000.
"""
METAINFO: dict = dict(from_file='configs/_base_/datasets/crowdpose.py')COCO 스타일의 데이터셋의 경우 BaseCocoStyleDataset을 상속하고 METAINFO를 지정하기만 하면 데이터셋 클래스가 사용할 준비가 된다.
▶ 3D Dataset
3D 데이터셋의 경우 BaseMocapDataset이라는 기본 클래스를 제공한다. 사용자는 BaseMocapDataset을 서브클래싱하고 필요에 따라 메서드(주로 __init__() 및 _load_annotations())를 재정의하여 새로운 사용자 정의 3D 키포인트 데이터셋으로 확장하는 것이 좋다.
파이프라인(Pipeline)
데이터 전처리 중 데이터 증강 및 변환은 파이프라인으로 구성된다. 다음은 일반적인 파이프라인의 예이다:
# 파이프라인
train_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
dict(type='RandomHalfBody'),
dict(type='RandomBBoxTransform'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
test_pipeline = [
dict(type='LoadImage'),
dict(type='GetBBoxCenterScale'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
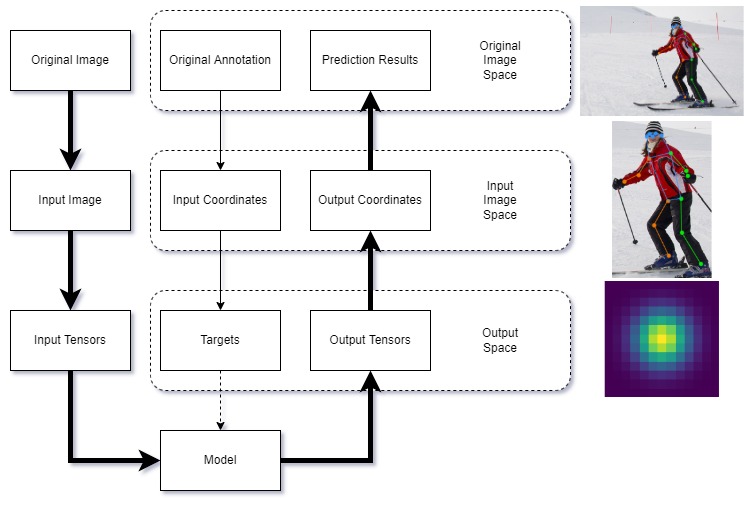
]키포인트 감지 작업에서 데이터는 세 가지 스케일 공간 간에 변환된다:
- 원본 이미지 공간: 원본 이미지와 주석이 저장되는 공간. 서로 다른 이미지의 크기가 반드시 동일할 필요는 없다.
- 입력 이미지 공간: 모델 입력에 사용되는 이미지 공간. 모든 이미지와 주석이 이 공간으로 변환된다(예: 256x256, 256x192 등).
- 출력 공간: 모델 출력이 위치하는 스케일 공간(예: 64x64 히트맵, 1x1 회귀 등). 훈련 중에는 감독 신호도 이 공간에 있다.
다음은 세 가지 스케일 공간 간 데이터 변환 워크플로우를 보여주는 다이어그램이다:
MMPose에서는 데이터 변환에 사용되는 모듈이 $MMPOSE/mmpose/datasets/transforms에 있으며, 그 워크플로우는 다음과 같다:
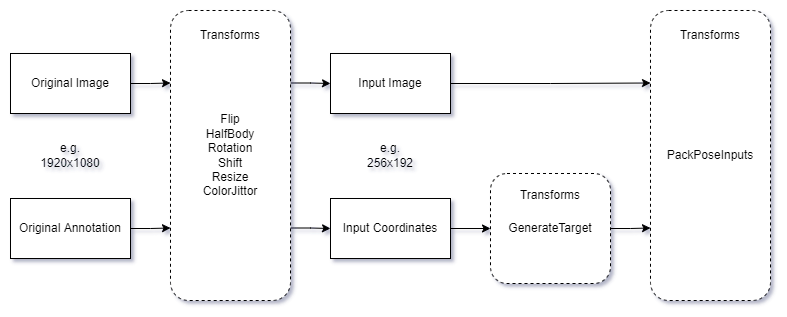
▶ 증강(Augmentation)
일반적으로 사용되는 변환은 $MMPOSE/mmpose/datasets/transforms/common_transforms.py에 정의되어 있으며, RandomFlip, RandomHalfBody 등이 포함된다. 탑다운 방식의 경우, Shift, Rotate 및 Resize는 RandomBBoxTransform에 의해 구현된다. 바텀업 방식의 경우, BottomupRandomAffine이 사용된다.
3D 포즈 데이터 변환은 $MMPOSE/mmpose/datasets/transforms/pose3d_transforms.py에 정의되어 있다.
▶ 변환(Transformation)
2D 이미지 입력의 경우, 원본 이미지 공간에서 입력 공간으로 이미지를 변환하기 위해 아핀 변환이 사용된다. 이는 탑다운 방식의 경우 TopdownAffine에 의해, 바텀업 방식의 경우 BottomupRandomAffine에 의해 수행된다.
포즈 리프팅 작업의 경우, 변환은 인코딩에 통합된다.
▶ 인코딩(Encoding)
훈련 단계에서는 데이터가 원본 이미지 공간에서 입력 공간으로 변환된 후, Gaussian 히트맵과 같은 학습 목표를 얻기 위해 GenerateTarget을 사용해야 한다. 이 과정을 인코딩이라고 한다. 반대로 Gaussian 히트맵에서 해당 좌표를 얻는 과정을 디코딩이라고 한다.
MMPose에서는 인코딩과 디코딩 과정을 Codec에 수집하며, 이 안에서 encode()와 decode()가 구현된다.
현재 다음과 같은 유형의 타겟을 지원한다.
- heatmap: Gaussian 히트맵
- keypoint_label: 키포인트 표현(예: 정규화된 좌표)
- keypoint_xy_label: 축별 키포인트 표현
- heatmap+keypoint_label: Gaussian 히트맵과 키포인트 표현
- multiscale_heatmap: 다중 스케일 Gaussian 히트맵
- lifting_target_label: 3D 리프팅 타겟 키포인트 표현
생성된 타겟은 다음과 같이 패킹된다.
- heatmaps: Gaussian 히트맵
- keypoint_labels: 키포인트 표현(예: 정규화된 좌표)
- keypoint_x_labels: 키포인트 x축 표현
- keypoint_y_labels: 키포인트 y축 표현
- keypoint_weights: 키포인트 가시성 및 가중치
- lifting_target_label: 3D 리프팅 타겟 표현
- lifting_target_weight: 3D 리프팅 타겟 가시성 및 가중치
탑다운, 포즈 리프팅 및 바텀업 방식을 통합한 데이터 형식을 통일했으며, 동일한 이미지에서 서로 다른 인스턴스를 나타내는 새로운 차원이 추가되었다. 형식은 다음과 같다:
[batch_size, num_instances, num_keypoints, dim_coordinates]- top-down and pose-lifting: [B, 1, K, D]
- bottom-up: [B, N, K, D]
▶ 패킹(Packing)
데이터가 변환된 후, PackPoseInputs를 사용하여 패킹해야 한다.
이 방법은 딕셔너리 결과에 저장된 데이터를 MMPose의 표준 데이터 구조(InstanceData, PixelData, PoseDataSample 등)로 변환한다.
구체적으로, 데이터를 gt(ground-truth)와 pred(prediction)로 나누며, 각 데이터는 다음과 같은 유형을 가진다:
- instances(numpy.array): 원본 스케일 공간에서 인스턴스 수준의 원시 주석 또는 예측
- instance_labels(torch.tensor): 출력 스케일 공간에서 인스턴스 수준의 학습 레이블(예: 정규화된 좌표, 키포인트 가시성)
- fields(torch.tensor): 출력 스케일 공간에서 픽셀 수준의 학습 레이블 또는 예측(예: Gaussian 히트맵)
다음은 PoseDataSample의 구현 예이다:
def get_pose_data_sample(self):
# 메타 정보
pose_meta = dict(
img_shape=(600, 900), # [h, w, c]
crop_size=(256, 192), # [h, w]
heatmap_size=(64, 48), # [h, w]
)
# gt_instances
gt_instances = InstanceData()
gt_instances.bboxes = np.random.rand(1, 4)
gt_instances.keypoints = np.random.rand(1, 17, 2)
# gt_instance_labels
gt_instance_labels = InstanceData()
gt_instance_labels.keypoint_labels = torch.rand(1, 17, 2)
gt_instance_labels.keypoint_weights = torch.rand(1, 17)
# pred_instances
pred_instances = InstanceData()
pred_instances.keypoints = np.random.rand(1, 17, 2)
pred_instances.keypoint_scores = np.random.rand(1, 17)
# gt_fields
gt_fields = PixelData()
gt_fields.heatmaps = torch.rand(17, 64, 48)
# pred_fields
pred_fields = PixelData()
pred_fields.heatmaps = torch.rand(17, 64, 48)
data_sample = PoseDataSample(
gt_instances=gt_instances,
pred_instances=pred_instances,
gt_fields=gt_fields,
pred_fields=pred_fields,
metainfo=pose_meta)
return data_sampleStep3: Model
MMPose 1.0에서 모델은 다음 구성 요소로 이루어져 있다:
- 데이터 전처리기: 데이터 정규화 및 채널 전환 수행
- 백본: 특징 추출에 사용
- 넥: GAP, FPN 등 선택 사항
- 헤드: 핵심 알고리즘 및 손실 함수 구현에 사용
모델에 대한 기본 클래스 BasePoseEstimator를 $MMPOSE/models/pose_estimators/base.py에 정의하였다. 모든 모델(예: TopdownPoseEstimator)은 이 기본 클래스를 상속하고 해당 메서드를 재정의해야 한다.
estimator의 forward()에서 세 가지 모드를 제공한다:
- mode == 'loss': 모델 훈련을 위한 손실 함수의 결과를 반환
- mode == 'predict': 모델 추론을 위한 입력 공간의 예측 결과를 반환
- mode == 'tensor': 모델 출력 공간의 모델 출력을 반환, 즉 모델의 순방향 전파만 수행, 모델 내보내기용
개발자는 해당 레지스트리를 호출하여 구성 요소를 빌드해야 한다. 탑다운 모델을 예로 들면:
@MODELS.register_module()
class TopdownPoseEstimator(BasePoseEstimator):
def __init__(self,
backbone: ConfigType,
neck: OptConfigType = None,
head: OptConfigType = None,
train_cfg: OptConfigType = None,
test_cfg: OptConfigType = None,
data_preprocessor: OptConfigType = None,
init_cfg: OptMultiConfig = None):
super().__init__(data_preprocessor, init_cfg)
self.backbone = MODELS.build(backbone)
if neck is not None:
self.neck = MODELS.build(neck)
if head is not None:
self.head = MODELS.build(head)
데이터 전처리기(Data Preprocessor)
MMPose 1.0부터 모델에 데이터 전처리기라는 새로운 모듈을 추가하였으며, 이미지 정규화 및 채널 전환과 같은 데이터 전처리를 수행한다. GPU와 같은 장치의 높은 계산 능력을 활용할 수 있으며, 모델 내보내기 및 배포의 일관성을 향상시킨다.
구성 파일에서의 일반적인 data_preprocessor는 다음과 같다:
data_preprocessor=dict(
type='PoseDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True),이는 입력 이미지의 채널 순서를 bgr에서 rgb로 변환하고, mean과 std에 따라 데이터를 정규화한다.
백본(Backbone)
MMPose는 $MMPOSE/mmpose/models/backbones 아래에 몇 가지 일반적으로 사용되는 백본을 제공한다.
실제로, 개발자는 전이 학습을 위해 사전 학습된 백본 가중치를 자주 사용하며, 이는 작은 데이터셋에서 모델 성능을 향상시킬 수 있다.
MMPose에서는 구성 파일에서 init_cfg를 설정하여 사전 학습된 가중치를 사용할 수 있다:
init_cfg=dict(
type='Pretrained',
checkpoint='PATH/TO/YOUR_MODEL_WEIGHTS.pth'),
백본에 체크포인트를 로드하려면 prefix를 지정해야 한다:
init_cfg=dict(
type='Pretrained',
prefix='backbone.',
checkpoint='PATH/TO/YOUR_CHECKPOINT.pth'),
checkpoint는 로컬 경로 또는 다운로드 링크일 수 있다. 따라서, Torchvision에서 제공하는 사전 학습된 모델(예: ResNet50)을 사용하려면 다음과 같이 간단히 사용할 수 있다:
init_cfg=dict(
type='Pretrained',
checkpoint='torchvision://resnet50')이러한 일반적으로 사용되는 백본 외에도 OpenMMLab 가족의 다른 리포지토리(MMClassification 등)에서 제공하는 백본을 쉽게 사용할 수 있으며, 이들은 모두 동일한 구성 시스템을 공유하고 사전 학습된 가중치를 제공한다.
새로운 백본을 추가하려면 다음과 같이 등록해야 한다:
@MODELS.register_module()
class YourBackbone(BaseBackbone):
pass또한 $MMPOSE/mmpose/models/backbones/init.py에 임포트하고, __all__에 추가해야 한다.
넥(Neck)
넥은 일반적으로 백본과 헤드 사이에 있는 모듈로, 일부 알고리즘에서 사용된다. 여기 몇 가지 일반적으로 사용되는 넥이 있다:
- 글로벌 평균 풀링(GAP)
- 피처 피라미드 네트워크(FPN)
- 피처 맵 프로세서(FMP)
FeatureMapProcessor는 백본에서 생성된 특징 출력을 헤드에 적합한 형식으로 변환하기 위해 비매개변수 연산(선택, 연결, 재스케일 등)을 사용하는 유연한 PyTorch 모듈이다. 아래는 몇 가지 예와 해당 구성이다:
- 선택 연산(Select operation)
neck=dict(type='FeatureMapProcessor', select_index=0)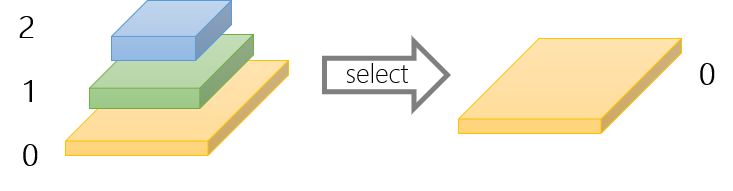
- 연결 연산(Concatenate operation)
neck=dict(type='FeatureMapProcessor', concat=True)
모든 피처 맵은 연결 전에 첫 번째 피처 맵(인덱스 0)의 모양에 맞게 크기가 조정된다.
- 재스케일 연산(Rescale operation)
neck=dict(type='FeatureMapProcessor', scale_factor=2.0)
헤드(Head)
일반적으로 헤드는 알고리즘의 핵심으로, 예측을 수행하고 손실 계산을 한다.
MMPose에서 헤드와 관련된 모듈은 $MMPOSE/mmpose/models/heads에 정의되어 있으며, 개발자는 BaseHead 클래스를 상속하고 다음 메서드를 재정의해야 한다:
- forward()
- predict()
- loss()
특히 predict() 메서드는 코덱이 제공하는 디코딩 기능을 통해 모델 출력에서 이미지 공간의 포즈 예측을 반환해야 한다. 이 과정은 BaseHead.decode()에 구현되어 있다.
또한 predict()에서는 테스트 시간 증강(TTA)을 수행할 것이다.
일반적으로 사용되는 TTA는 flip_test이며, 이미지와 그 뒤집힌 버전이 모델로 들어가서 추론을 수행하고, 뒤집힌 버전의 출력은 다시 뒤집힌 후 평균을 내어 예측을 안정화한다.
다음은 RegressionHead에서 predict()의 예이다:
def predict(self,
feats: Tuple[Tensor],
batch_data_samples: OptSampleList,
test_cfg: ConfigType = {}) -> Predictions:
"""Predict results from outputs."""
if test_cfg.get('flip_test', False):
# TTA: flip test -> feats = [orig, flipped]
assert isinstance(feats, list) and len(feats) == 2
flip_indices = batch_data_samples[0].metainfo['flip_indices']
input_size = batch_data_samples[0].metainfo['input_size']
_feats, _feats_flip = feats
_batch_coords = self.forward(_feats)
_batch_coords_flip = flip_coordinates(
self.forward(_feats_flip),
flip_indices=flip_indices,
shift_coords=test_cfg.get('shift_coords', True),
input_size=input_size)
batch_coords = (_batch_coords + _batch_coords_flip) * 0.5
else:
batch_coords = self.forward(feats) # (B, K, D)
batch_coords.unsqueeze_(dim=1) # (B, N, K, D)
preds = self.decode(batch_coords)
loss() 메서드는 손실 함수의 계산뿐만 아니라 포즈 정확도와 같은 훈련 시간 지표의 계산도 수행한다. 결과는 losses 딕셔너리에 담긴다:
# 정확도 계산
_, avg_acc, _ = keypoint_pck_accuracy(
pred=to_numpy(pred_coords),
gt=to_numpy(keypoint_labels),
mask=to_numpy(keypoint_weights) > 0,
thr=0.05,
norm_factor=np.ones((pred_coords.size(0), 2), dtype=np.float32))
acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
losses.update(acc_pose=acc_pose)
각 배치의 데이터는 batch_data_samples에 패키징된다. Regression 기반 방법을 예로 들면, 정규화된 좌표와 키포인트 가중치를 다음과 같이 얻을 수 있다:
keypoint_labels = torch.cat(
[d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
keypoint_weights = torch.cat([
d.gt_instance_labels.keypoint_weights for d in batch_data_samples
])
다음은 RegressionHead에서 loss()의 전체 구현이다:
def loss(self,
inputs: Tuple[Tensor],
batch_data_samples: OptSampleList,
train_cfg: ConfigType = {}) -> dict:
"""Calculate losses from a batch of inputs and data samples."""
pred_outputs = self.forward(inputs)
keypoint_labels = torch.cat(
[d.gt_instance_labels.keypoint_labels for d in batch_data_samples])
keypoint_weights = torch.cat([
d.gt_instance_labels.keypoint_weights for d in batch_data_samples
])
# 손실 계산
losses = dict()
loss = self.loss_module(pred_outputs, keypoint_labels,
keypoint_weights.unsqueeze(-1))
if isinstance(loss, dict):
losses.update(loss)
else:
losses.update(loss_kpt=loss)
# 정확도 계산
_, avg_acc, _ = keypoint_pck_accuracy(
pred=to_numpy(pred_outputs),
gt=to_numpy(keypoint_labels),
mask=to_numpy(keypoint_weights) > 0,
thr=0.05,
norm_factor=np.ones((pred_outputs.size(0), 2), dtype=np.float32))
acc_pose = torch.tensor(avg_acc, device=keypoint_labels.device)
losses.update(acc_pose=acc_pose)
return losses
'OpenMMLab > MMPose' 카테고리의 다른 글
| [MMPose] Overview (0) | 2024.06.22 |
|---|---|
| [MMPose] Installation (0) | 2024.06.14 |
